0 引言
随着电网内大量二次设备的接入,过去单一的点对点通信方式已不能满足现有电力通信网的发展。电网智能化及应用集中部署也使得电网生产、调度、营销、管理业务需求不断增多,单一依靠流量统计已不能满足现有业务对传输网和传输设备的需求[1-2]。因此,根据承载方式的不同对电力业务进行分类,同时按照不同类型的业务需求对其通信带宽流量进行预测,既能够有效地解决网络拥塞,也能提高电力通信网络的利用率[3]。
目前,现有的带宽预测方法中,线性预测方法是最常用的,通过简单地计算业务的平均值、最大值累加,或者统计预测过去某时间段业务流量趋势,来对电网通信带宽进行预测。但由于同一天内不同业务之间的流量分布情况不一定相同,因此这种方法的准确性不高[4]。根据电话业务的特征提出的泊松模型,因能够准确描述电话网中业务特性而得到广泛应用。但该模型更多用于传统的电话交换网,由于数据通信流量具有突发性,因此泊松模型不适合用于数据网络流量分析。基于研究统计规律的自回归滑动平均模型(Auto Regressive and Moving Average Model,ARMA)是以自回归模型(AR模型)与滑动平均模型(MA模型)为基础,采用历史值预估未来值。但是其对于业务的发展敏感性低,无法较好地反映业务变化对网络带宽造成的影响[5]。反向传播(Back Propagation,BP)神经网络是目前应用最广泛的神经网络模型之一,通过对大量数据的学习和存储来寻找输入-输出之间的映射关系,但BP神经网络容易受到数据量和自身节点数目的限制,造成算法运行时间长、运行结果偏差较大等问题。
现今电力通信网络承载业务种类多、实时数据量大,单一或者浅度的学习算法对其带宽流量的预测准确性不够,同时对于大量的带宽流量数据使用率不高,运行时间较长。深度学习模型在面对越来越庞大的数据量时基本不存在过饱和状态,数据越多越能获得更好的学习效果,可最大程度发挥大数据量的优势。
因此,本文依托某省电力公司“十二五”期间通信网络建设[6],结合其电力通信业务的种类及历史流量,对其通信网络承载业务进行分析;同时采用深度学习方法,建立不同业务的流量模型,对某省电力通信网未来带宽流量进行预测。根据业务需求预测结果,分析现有通信网存在的问题,进而开展对数据通信网络建设的思考及其发展规划的建设。
1 现有电力通信网络承载业务分析
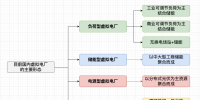
根据承载方式不同,现有电力通信网络业务可划分为3个类别:专线通信、调度数据网和综合数据网。具体分类为:点到点专用光纤通道所承载的业务;调度数据网承载的电力系统生产直接相关的业务;综合数据网承载的电力系统生产管理服务业务[7-8]。
1.1 专线通信承载业务
专线通信业务主要是指由电力专用光纤传输网承载的业务,特指电力系统专线通信业务——点到点的专用光纤通道,为电网安全稳定运行必不可少的核心业务。例如调度电话、电力系统继电保护、电力系统远方保护、安全自动装置等,主要功能是承载各类远方保护及安全稳定控制信号的传输。
1.2 调度数据网承载业务
调度数据网业务是指与电力自动化生产直接相关的业务,例如信息保护管理系统、信息安稳管理系统、广域相量测量系统、电力市场技术支持系统等。这些业务对数据传输的可靠性、安全性要求较高,同时相对于专线通信业务,其传输时延要求较低。
1.3 综合数据网承载业务
综合数据网承载的业务主要是为生产管理服务,包括企业管理信息化业务、变电站图像/通信机房设备监视系统、视频会议系统、调度管理信息系统等。这些业务对信号传输性能和安全、信号传输可靠性等要求较高,同时相较于专线通信业务,其传输时延要求较低。因此,必须为其提供可靠的传输路径和充足的带宽量。
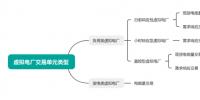
针对不同类型业务按照其对应的统计方法对通信带宽进行统计,得到其带宽需求量的历史数据,并同时统计影响通信带宽预测因素的体系数据。将现有某省电力通信网传统业务归类,同时对其新业务(如调度数据网第二平面建设、输电线路状态监测、变电站视频监测、配网自动化高清会议系统等)进行分析和分类,本文基于业务系统的相似性及业务系统的现有模型,选取5个典型业务系统(管理信息化业务、视频会议业务、语音业务、互联网业务、新增业务)对通信带宽预测模型进行建模,分析网络带宽需求,同时这也是新增业务带宽预测的基础。
2 基于深度学习的电力通信网络带宽需求预测
深度学习模型相对于浅度学习模型(如神经网络、支持向量机等)而言,是一种包含多个隐藏层的机器学习模型。深度学习模型由Hinton等人于2006年提出,通过利用大量数据进行训练,学习获得有用的特征,进而广泛应用于图像处理和语音识别等方面。区别于浅度学习,使用深度学习模型在面对越庞大的数据量时越能获得更好的学习效果,不存在过饱和状态,无需考虑过拟合的问题,可最大程度发挥大数据量的优势。同时,深度学习模型在突出特征学习重要性的基础上,还利用逐层特征变换方法,将原空间样本特征变换到一个新的特征空间内,易于实现样本的预测或分类[9]。
由于现有电力通信网络承载的业务种类多,实时数据量大,简单的浅度学习算法对其带宽流量的预测具有很大的不准确性,同时浪费了大量的带宽流量数据[10]。为了提高通信网络带宽流量预测的准确度,定性、定量判断带宽需求,本文选用深度学习方法,针对某省电力通信网5个典型业务分别建立预测模型,综合分析预测模型结果,预测该省电力公司下一阶段的带宽需求,同时也考虑了特殊业务对带宽的需求,如互联网访问业务、FTP业务、视频语音业务等。
2.1 预测模型结构
本文采用深度学习方法中的深度玻尔兹曼机模型(Deep Boltzmann Machines,DBMs)建立预测模型,其中DBMs是指堆叠多个限制玻尔兹曼机(Restricted Boltzmann Machines,RBM)。RBM的构成可分为两部分,即输入数据层和隐藏层。每层内节点之间无连接,且只能随机在0和1取值,其全概率分布满足Boltzmann分布[11-12]。DBM模型结构如
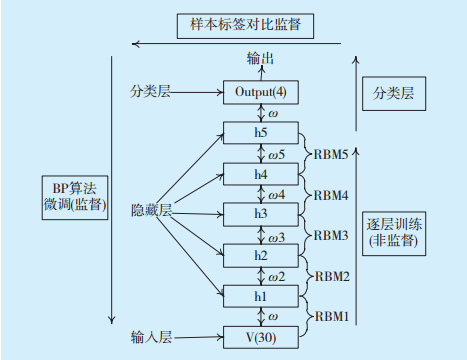 图1 DBM模型结构Fig. 1 The structure of DBM
图1 DBM模型结构Fig. 1 The structure of DBM
通过多次试验,本文采用1个输入层、1个输出层和5个隐藏层的RBM模型结构,迭代次数为20次。输入层节点数与不同业务系统的主要影响因素个数有关,隐藏层节点个数为输入层节点数的一半,同时用ωi(i=1,2,…,5)分别表示5个隐藏层的权值,ω表示输出层的权值。输入层为影响带宽流量的因素,输出层为带宽流量,表示当前典型业务的带宽流量。对于本预测模型而言,利用大量的数据样本训练低层RBM模型的每一层,然后训练上层分类层,最后通过BP算法微调整个网络。
2.2 模型训练策略
与传统神经网络相比,深度学习引入了预训练概念,初始权值通过利用自下而上的非监督学习获得,然后再通过自上而下的监督学习优化参数。深度学习法主要分为2个阶段:预训练阶段和微调阶段[12]。
2.2.1 预训练阶段
深度学习的预训练过程是一种非监督学习过程,利用预训练网络能够获得算法的初始权值,逐层贪婪优化为其训练策略。RBM的可视层为v和隐层为h,同时层内节点彼此对立,层间节点全部互相
连接。
RBM随机模型的能量函数和概率分布函数可表示为:
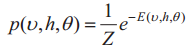
式中,vi为可视层节点状态;hi为隐层节点状态;ai、bi为相应层节点偏置;ωi,j为节点之间的连接权值;θ={W,a,b}为网络权值,即该阶段需要优化的参数;Z是归一化系数,其表达式为:
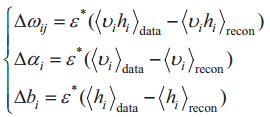
式中,ε为学习率;<*>data为样本期望;<*>recon为RBM重构后的期望。
通过上述过程,能够获得与输入数据分布类似的输出。通过优先训练最低层RBM,并将影响因素个数作为输入,得到带宽流量的表述h1,然后以h1作为输入,训练第二层RBM,以此类推。输出层是Softmax分类器,通过样本比较随机初始化输出层权值ω。
2.2.2 微调阶段
预训练后,RBM模型获得了一个初始权值,但不一定是模型的最优权值,因此需要对初始权值进行微调。本文选用BP神经网络算法[10],与样本数据比较,自顶向下对网络参数进行微调,其调整过程的目标函数如下:
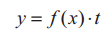
业务流量y是由时间t和用户数x组成的相关函数。
同时,使用该业务的用户数x是由总用户数A及时间t组成的相关函数:
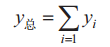
深度学习法主要是在带宽流量预测过程中寻找出原始数据和时间的关系方程。
3 基于主元分析法的带宽预测影响指标简化分析
在电力通信网络带宽预测中存在很多影响因素,不同的预测方法对提炼样本数据信息的复杂性、数据要求等方面均有不同,常规考虑多影响因素的预测方法无法完全描述各因素对预测对象的影响[13]。本文选用的深度学习法可以不必处理影响因素,可直接将其作为输入数据就可进行考虑多因素的预测。由于深度学习是一个对数据不断挖掘的过程,随着挖掘的深入,若输入节点过多,则很有可能造成结果不收敛,而输入节点过少则会造成预测不准确。因此,综合考虑电力业务带宽历史数据特点以及其影响因素,本文提出首先采用主元分析法对电力通信带宽预测影响因素数据进行简化[