本文讲的回声(Echo)是指语音通信时产生的回声,即打电话时自己讲的话又从对方传回来被自己听到。回声在固话和手机上都有,小时还可以忍受,大时严重影响沟通交流,它是影响语音质量的重要因素之一。可能有的朋友要问了,为什么我打电话时没有听见自己的回声,那是因为市面上的成熟产品回声都被消除掉了。
回声分为线路回声(line echo)和声学回声(acoustic echo),线路回声主要存在于固话中,是由于2-4线转换引入的回声,声学回声是由于空间声学反射产生的回声 。回声消除(Echo canceller, EC)是语音前处理的重要环节,下面主要讲其基本原理和调试中的一些经验。
1、基本原理
1)自适应滤波器和自适应算法
一般滤波器的系数是固定的,而自适应滤波器的系数是变化的,是依据自适应算法来调整滤波器系数的。自适应滤波器的结构采用FIR或IIR均可,由于IIR存在稳定性问题,因此一般采用FIR。
下图是自适应滤波器的一般结构:
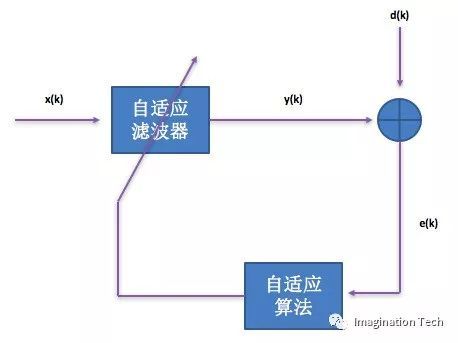
上图中,x(k)为输入信号,y(k)为输出信号,d(k)为期望信号,e(k)是d(k)和y(k)的误差信号。自适应滤波器的滤波器系数受误差信号e(k)控制,根据e(k)的值和自适应算法自动调整。
自适应算法一般采用LMS(least mean square,最小均方)算法及其变种(如NLMS算法)。LMS算法是随机梯度算法族中的一员。具体可以看相关的文章。
2)回声消除基本原理。
下图是回声消除基本原理的框图:
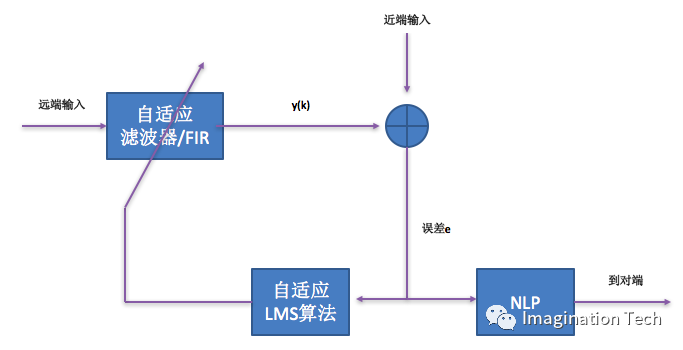
处理过程如下:
a) 算近端远端语音数据的energy,确定双方是silent还是talk。
b) 远端输入经过自适应FIR滤波器后就得到了近似于近端输入的数据,并与近端输入相减后得到了误差e。误差e作为自适应LMS算法的输入在需要的时候去更新自适应FIR滤波器的系数给后面远端数据处理用。在需要的时候是指远端talk近端silent的情况,其他情况(比如double silent / double talk)下不需要更新FIR滤波器的系数。
c) 误差e同时也会经过NLP(非线性处理)后产生舒适噪声送给对方。
2、调试
EC相对较难,要做的很好很不容易。在webRTC开源前主要是大公司和专业的算法公司有好的实现方案,一般公司要想产品里有EC就去买算法库。webRTC开源后一些核心的算法(包括AEC/ANS/AGC等)也随之开源,这样众公司开始用webRTC里的算法,尤其是互联网公司,AEC等算法基本都是用的webRTC的。
本人有两次EC的调试经历。第一次是在芯片公司,做语音解决方案。从公司的算法部门拿来了回声消除实现,把它用到解决方案中。另一次是在移动互联网公司,做实时语音通信类APP,要把webRTC的AEC用到APP中。第一次花的时间较多,要学习原理,看算法代码,做应用程序验证算法并且要修改系数,在产品上调试等。第二次有了第一次的基础再加上webRTC封装的较好从而花的时间较短。个人觉得对EC零基础但已有EC算法代码的基础上去调试主要有如下几步:
1)学习回声消除的基本原理,涉及信号处理知识(从固定系数滤波器到系数自适应滤波器)和高等数学知识(梯度)等。因为不是做算法,掌握基本的就可以了。如果基础扎实,当然搞得越明白越好了。
2)看算法代码。如果有实现的设计文档那是最好了,好多算法实现有技巧,有设计文档的话能更好的帮助理解代码。没有只能硬着头皮啃了。刚开始可能有些看不懂,多看几遍,也许每一次都会多懂一些。
3)做个应用程序验证算法。这个应用程序输入是近端和远端的PCM文件,把EC的输出写进一个PCM文件里,看处理效果如何。这里面也可以分几小步:
a) 设latency为零,近端和远端的PCM文件相同,理论上输出是全零数据。如果是这样,恭喜你选择的算法有一个好的base。如果不是那就需要去调算法里的一些系数了,这也许要调好多次,最终调试结果要是算法输出基本听不见回声。
b) 设一定的latency,近端的PCM和远端的数据一样,但是近端的PCM数据相对远端的有一定的delay,这个值跟设定的latency值是一样的,这时理论上输出还是全零数据。
c) 获取实际产品上的近端和远端PCM数据,可以近似得到近端和远端的latency。把这几个作为输入,看算法输出,也要基本听不见回声。这步调好后算法基本上就可以用了。
4)在具体硬件平台上去调。每个硬件平台上的latency都是不一样的。在芯片公司时有demo板,每个客户也有他们的电路板,硬件平台相对不多一个个获取近远端PCM数据调好latency就可以了。在移动互联网公司做APP时,手机类型众多,用上面方法太累,于是在UI上做了一个滑动条去配置latency,让测试人员去测试找到一个相对较好的latency,然后放在配置文件里保存下来,以后这款手机就用这个latency值了。
经过上面几步后在真正产品上的EC调试就算结束了。