0 引言
电力设备在线监测系统能够对设备运行状况进行连续或周期性的自动监视和检测。随着智能电网建设的进步,电力设备在线监测取得了很大发展,监测数据的规模也变得日益庞大,逐渐形成电力设备监测大数据[1],这给在线监测系统在数据存储和数据处理方面带来了新的技术挑战,主要体现在以下几个方面。
1)数据体量巨大。电力设备监测大数据正从TB级向PB级别跃迁,造成数据体量巨大的主要原因是监测的广度大、监测点数量多以及数据采样率高。另外,电力设备监测的深度也不断提升,监测类型逐渐多样,包括变压器局部放电、油色谱、线路覆冰监测、绝缘子泄漏电流、电站视频监测等,进一步导致了监测数据的体量非常巨大。
2)数据种类繁多。需要存储和处理的数据既包括结构化的采样数据和静态关联数据,又包括非结构化的采集数据,如音视频数据等;另外还有用XML、JSON等格式承载的半结构化数据,这给存储系统带来很大的技术挑战。
3)要求快速完成数据分析。在完成监测数据采集后,需要一个大数据处理平台来完成包括数据清洗、格式转换、数据去噪、特征计算等一系列批量计算任务,这些任务通常是自动定时触发的,必须在规定的时间内完成分析任务,否则会影响后续的数据分析过程。
4)平台的选择。大数据平台应能有效支持多种大数据计算场景,包括批量计算、在线计算和流式计算,且应能支持高效的数据交互和广泛、多源的数据集成方案。
目前,电网公司监测系统过于依赖集中式存储区域网络(Storage Area Network,SAN)存储,并基于SOA进行数据集成。存储软件主要采用企业级关系型数据库,在存储容量、扩展性以及访问速度方面均无法满足电力设备监测大数据存储和数据处理的需求。另一方面,关系型数据库所擅长的关联查询、主外键约束、事务处理等特性在进行大数据分析时又无用武之地,这就迫切需要新的大数据存储和处理技术以及新的平台来应对。
针对上述问题和挑战,本文采用全新的MaxCompute大数据处理技术,在阿里云云计算平台上进行数据存储和数据处理,以大规模的变压器局部放电数据为例,设计数据存储方法和快速的并行分析方法。
1 电力系统中的批量计算
MaxCompute是阿里云提供的海量数据处理平台,支持批量结构化、非结构化数据的存储和计算,数据规模可达EB级别。MaxCompute目前已在电子商务网站的交易分析、企业数据仓库和BI分析等领域得到广泛应用。MaxCompute提供了数据上传下载通道(Tunnel),以及SQL、MapReduce、Graph等多种计算服务接口。MaxCompute功能组件如
批量计算是指对历史数据进行周期性的、用户发起或者定时触发的计算。批量计算每次处理的数据量通常较大,并追求高吞吐量,对交互性、实时性要求较低。批量计算模型如
 图1 MaxCompute功能组件Fig.1 MaxCompute functional components
图1 MaxCompute功能组件Fig.1 MaxCompute functional components
 图2 批量计算模型Fig.2 Batch calculation model
图2 批量计算模型Fig.2 Batch calculation model
目前典型的批量计算工具有Hadoop Map Reduce、Spark、阿里云MaxCompute等。批量计算在电力系统中的应用需求非常大,应用最多的计算工具是Hadoop。文献[2]应用Hadoop设计实现了一种层次化的电压暂降并行计算方法,提高了海量电能质量监测数据的计算效率。文献[3]应用Hadoop设计实现了变断面量测数据的快速无损数据压缩。文献[4-5]应用Hadoop设计实现了并行化的极限学习机,并实现了短期电力负荷预测。文献[6]应用Hadoop实现了并行化的数据分析和负荷预测。文献[7-8]应用Hadoop实现了海量电能质量监测数据的并行化查询。文献[9]基于并行化的贝叶斯分类器,实现了变压器的故障诊断,使诊断速度有了很大的提升。
2 使用MaxCompute实现电力设备监测数据的高效存储
2.1 监测数据的存储模式设计
监测数据的原始值往往是二进制的采样数据,以dat文件形式存在[10-11],MaxCompute存储数据的基本单元是表(table)。为了完成数据分析,需要首先将监测数据上传至MaxCompute。由于MaxCompute无法支持二进制数据的自动解析,上传之前需要先将其转换成文本文件格式,如csv文件,再使用Tunnel工具进行数据上传。
如果使用普通文本文件存储监测数据,则每行可以存储一个完整采样周期的数据[12],例如一行文本可以存储10万个采样点的数据。该文本可在HDFS上被MapReduce分析任务直接处理。但MaxCompute对表的列数和表格单元的数据类型有限制,表格单元目前支持的数据类型无法在一行内存储数万个采样值,这需要重新设计表结构。
本文进行了横纵转换设计,将常见的“横表”改为“纵表”,用于存储原始采样数据。由于MaxCompute不支持索引,为了最大程度提升数据分析性能,在存储设计方面还使用了多级分区技术。使用二级分区的监测大数据存储模式如
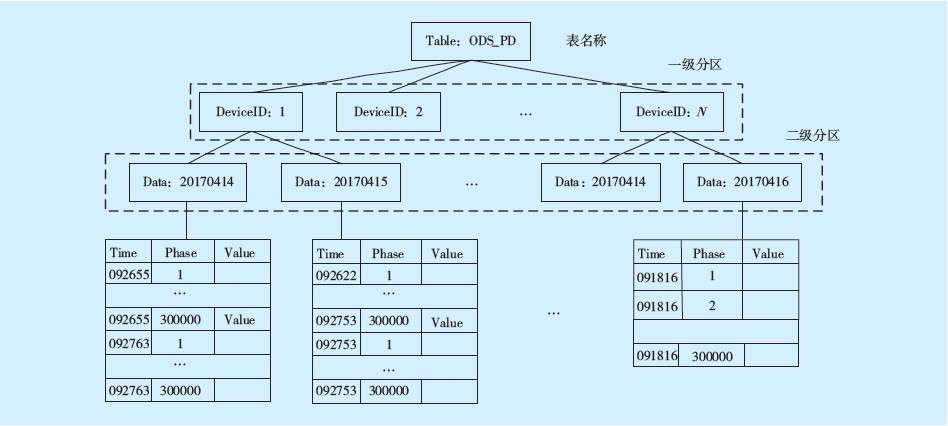 图3 使用二级分区的监测大数据存储模式Fig.3 The monitoring big data storage mode using secondary partition
图3 使用二级分区的监测大数据存储模式Fig.3 The monitoring big data storage mode using secondary partition
电力设备监测数据的两个最基本属性是设备编号和数据采集时间。为了提升查询和数据分析的性能,使用设备ID作为一级分区,采集日期作为二级分区,从而可以有效减少数据查询的范围,提升访问性能。
2.2创建MaxCompute项目
项目是MaxCompute的基本组织单元,通常一类特定的数据分析任务需创建一个项目,并将相关的数据表和资源都放入到该项目中[13]。为了完成项目创建,需要首先使用已有的阿里云账号登录阿里云管理控制台,进入MaxCompute管理控制台,创建一个新的MaxCompute项目。阿里云管理控制台如
 图4 阿里云管理控制台Fig.4 Ali cloud management console
图4 阿里云管理控制台Fig.4 Ali cloud management console
 图5 创建项目选项Fig.5 Project creating options
图5 创建项目选项Fig.5 Project creating options
如果不是长期运行计算任务,可以选择“I/O后付费”,填入项目名称和项目描述,创建项目。创建项目选项如
2.3 创建分区表并添加分区
2.3.1 配置客户端
为了创建所设计的分区表并实现数据上传,需要首先安装并配置ODPS cmd客户端工具。这需要在本地准备好JRE 1.6+版本环境,并从阿里云官网下载ODPS cmd工具,并配置<ODPS_CLIENT>/conf/odps_config.ini文件,具体如下:
project_name=[project_name]
access_id=***
access_key=***
end_point=http://service.odps.aliyun.com/api
tunnel_endpoint=http://dt.odps.aliyun.com
log_view_host=http://logview.odps.aliyun.comhttps_check=true
access_id和access_key可从阿里云管理控制台获取,project_name配置为创建好的MaxCompute项目即可。配置完成后,运行<ODPS_CLIENT>/bin/odpscmd,进入交互模式,会出现项目名称作为提示符。ODPS cmd控制台如
 图6 ODPS cmd控制台Fig.6 The ODPS cmd console
图6 ODPS cmd控制台Fig.6 The ODPS cmd console
ODPS cmd控制台运行成功后即可执行创建分区表操作,本文使用SQL DDL语句进行创建数据分区表、添加分区的操作,以变压器的局部放电数据为例来介绍数据存储的方法和宏观统计特征的计算方法。
2.3.2 创建数据表并添加分区
在ODPS cmd中,执行SQL语句建表,并添加分区,用于存储监测数据和中间结果数据,具体如下:
create table if not exists ODS_MData(
Time string, ---’采集时间’
Phase bigint, ---’相位’
Value bigint, ---’采样值’
partitioned by (DeviceID string, Date string);
alter table ODS_MData add if not exists partition (DeviceID=‘001’, Date=‘20170625’);
使用相同的SQL语法,依次创建基本参数表DW_NQF和放电谱图表DW_PT,数据表字段描述见
 表1 数据表字段描述Tab.1 Data table field description
表1 数据表字段描述Tab.1 Data table field description
2.4 使用Tunnel进行数据上传
在ODPS cmd中运行tunnel命令,将监测数据文件上传至MaxCompute表,具体命令如下:
tunnel upload d:/Clouder/jfdata/jf.csv ODS_MData/deviceid =’001’, Date=‘20170625’ ;
命令中的路径在执行时需根据实际路径进行修改。使用Tunnel进行数据上传如
 图7 使用Tunnel进行数据上传Fig.7 Using Tunnel for data upload
图7 使用Tunnel进行数据上传Fig.7 Using Tunnel for data upload
在上传完成之后,可以使用read或者select命令验证数据是否已经存在。
3 使用MapReduce实现监测数据特征计算
3.1 监测数据特征计算的总体流程
为了实现对监测数据的统计特征计算,需要使用2个MapReduce任务来完成计算,并将计算任务串联起来。为了完成任务串联和任务调度的周期执行,本文使用阿里云数加平台的大数据开发套件来设计实现计算任务的工作流,并配置任务调度策略。特征计算的工作流和调度配置界面如
 图8 特征计算的工作流和调度配置界面Fig.8 Feature computing work flow and scheduling configuration interface
图8 特征计算的工作流和调度配置界面Fig.8 Feature computing work flow and scheduling configuration interface
在工作流中,Data_synchronization节点用于执行数据同步任务,DW_NQF节点用于完成基本参数的计算,DW_PT节点用于计算谱图特征。在调度策略配置上,设置为每天0点执行一次任务调度。DW_NQF节点和DW_PT节点都是MapReduce程序,需要首先在本地进行程序开发和测试,成功后才能上传至云平台执行。
3.2 本地开发环境准备
本文使用Eclipse作为开发环境,并需要使用ODPS for Eclipse开发插件。启动Eclipse,检查Wizard选项中是否有ODPS的目录。当可以创建ODPS类型的项目时,表明本地开发环境已准备好。
3.3 MapReduce程序开发
3.3.1 基本参数的计算
本文设计了MapReduce程序实现基