0 引言
近年来,随着国家电网公司“三集五大”体系的推进,以及SG186、SG-ERP工程的建设,公司信息化实现了由分散到集中、由孤岛到共享的转变,积累了生产运行数据和经营管理数据约5 PB,每月平均增长数据量约46 TB,为数据集中共享和大数据分析、价值挖掘提供了有利条件[1]。但是,数据资源中往往携带着有关用户与企业的敏感、隐私信息,一旦遭遇泄露、篡改,将给个人及公司甚至国家造成无法挽回的损失。因此,在数据共享使用过程中,如何准确定位敏感数据,合理制定脱敏策略,以达到数据安全可信、受控使用的目标,是一项亟待解决的技术问题。
数据安全问题的形势越来越严峻,数据脱敏逐渐受到企业的重视。传统的数据脱敏研究大多侧重于脱敏方法的实现[2-4],缺少权限判决、敏感识别等功能,系统化水平不够高。同时,脱敏算法的选择多为人工指定和自定义配置,智能化水平不够高。此外,模式识别的发展对实现脱敏信息的自动识别提供了技术支持[5],但在敏感信息分类定级问题上缺少对企业需求的考虑,专业化水平不高。
为解决数据脱敏的系统化、智能化、专业化水平不足等弱点,本文提出了一种独立于其他专业系统之外的数据脱敏系统。该系统同时集成了权限判决、数据分类、敏感信息识别、脱敏任务执行等功能;在敏感信息识别、敏感算法选择等关键环节采用文本分类、决策树等机器学习方法,可辅助人工实现脱敏策略制定;采用两层分类方式分类定级敏感信息,第一层按数据的专业和类型分类,第二层按规则进行分类定级。相较于传统数据脱敏方式,本文提供了一种智能化设计数据脱敏系统的新思路。
1 数据脱敏简介
数据脱敏又可称为数据去隐私化、数据变形,是指在保留数据初始特征的条件下,按需制定脱敏策略和任务,对敏感数据进行变换、修改的技术机制,可以在很大程度上解决敏感数据在非安全环境下使用的问题[6]。数据脱敏实现的难点在于如何同时保障数据的安全及其可用性,其关键就是脱敏算法的选择,就现阶段而言更多的是一种经验决策。根据不同的作用位置和实现原理,脱敏任务可分为静态脱敏(Static Data Masking,SDM)和动态脱敏(Dynamic Data Masking,DDM)。SDM一般用于非生产环境,在应用开发、测试、培训等场合中,为规避泄露风险,数据必须脱敏后才能被存储及使用。DDM常用于生产环境,当敏感数据被分析工具在线访问时,脱敏系统可以按照策略执行相应的脱敏算法。简言之,DDM与SDM的区别在于是否是在使用敏感数据时才进行脱敏。
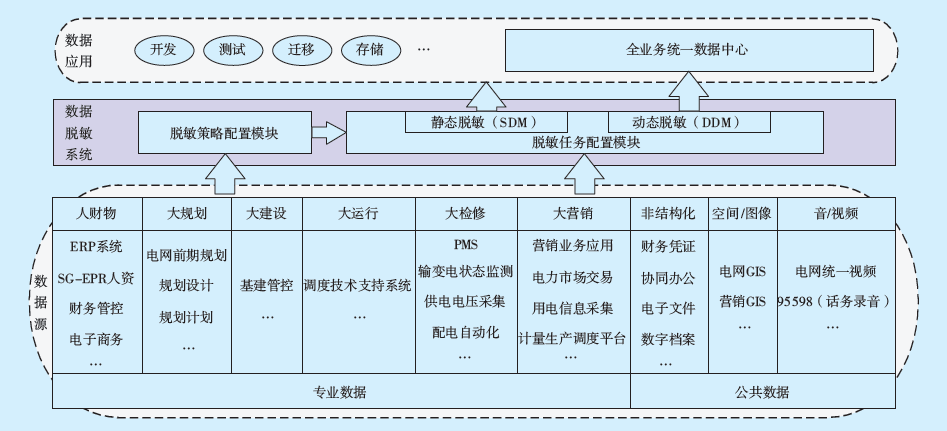 图1 数据脱敏系统应用框图Fig.1 Application block diagram for data masking system
图1 数据脱敏系统应用框图Fig.1 Application block diagram for data masking system
数据脱敏系统应用框图如
2 脱敏策略制定
从源系统抽取数据后,脱敏系统要为这些数据制定合适的脱敏策略。在策略制定阶段,系统需要着力解决敏感数据如何定级、是否需要脱敏、如何脱敏等一系列问题。
2.1 源数据分类及预处理
2.1.1 源数据分类
脱敏策略制定流程如
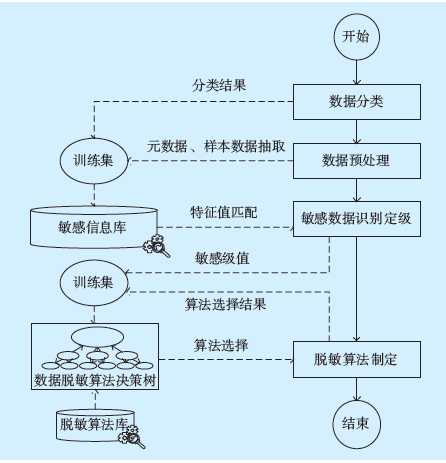 图2 脱敏策略制定流程Fig.2 Flow chart of masking strategy formulation
图2 脱敏策略制定流程Fig.2 Flow chart of masking strategy formulation
2.1.2 数据预处理
对源数据进行预处理以提取数据特征,通过数据特征匹配实现敏感信息识别[9]。脱敏系统采用自动化方式采集关系型数据库和非结构化系统的数据样本和元数据。结构化数据以数据字典(包括表名和字段名、类型、注释)的形式进行采集,并通过数据表遍历的方法从业务数据表中采集一定数量的样本数据。文本数据采用文本分词的方法对样本进行切割与合并,构建文本文件特征。对于图片、语音、视频数据,则通过相应领域的模式识别方法进行元数据和样本提取。元数据和样本采样完成后样本质量往往不佳,需要对其进行过滤和泛化处理,剔除数据“杂质”,以降低敏感信息识别与分类过程中的计算量[10]。
2.2 敏感数据识别定级
敏感数据识别是实现数据脱敏的关键前提。针对不同文件格式的数据,其敏感特征的检测方法会有所差异,数据脱敏系统应对其样本数据和元数据进行分类训练,最后分类建立敏感信息库。
敏感信息识别过程如
 图3 敏感信息识别过程Fig.3 Sensitive information recognition process
图3 敏感信息识别过程Fig.3 Sensitive information recognition process
2.3 脱敏策略制定
2.3.1 常用的脱敏方法
1)替换。替换(Replacement,RP)是指利用伪装数据对源数据中的敏感数据进行完全替换。为保证安全,一般替换用的数据都不具可逆性。
2)加密。加密(Encryption,EC)是指对待脱敏的数据进行加密处理,使外部用户或系统只能够接触无意义的加密数据。在特定场景下,系统可以提供解密能力,分发密钥给相关方以恢复原始数据。
3)遮掩。遮掩(Masking,MK)是指利用掩饰符号对敏感数据的部分内容进行统一替换,使得敏感数据保持部分内容公开。
4)删除。删除(Deletion,DL)是指直接删除敏感数据或将其置为空。
5)变换。变换(Change,CG)是指通过随机函数对数值和日期类型等源数据进行可控调整,以便在保持原始数据相关统计特征的同时,完成对具体数值的伪装。
6)混洗。混洗(Shuffle,SF)主要是指通过对敏感数据采取跨行随机互换来打破其与本行其他数据的关联关系,从而实现脱敏。
2.3.2 数据脱敏需考虑的因素
数据脱敏的最大难点在于平衡隐私保护和数据挖掘需求,脱敏算法适当与否直接影响到脱敏效果。为了制定合适的脱敏算法,结合具体应用场景,本文重点考虑了以下几个因素[12]。
1)可用性。即脱敏后的数据应能满足分析应用需求,若脱敏后的数据无法用于目标分析及应用,就不具备使用价值。在特定应用场景中,可能需要保留部分非关键信息(如身份证号码、手机号码的部分字段等)才能满足分析需求。
2)关联性。对于结构化和半结构化数据,在同一数据表中某字段与另外字段有对应关系,如果脱敏算法破坏了这种关系,该字段的使用价值将不复存在。通常在进行数据统计需要参考量的情况下,对数据的关联性要求较高。
3)真实性。脱敏后的数据对原始数据逻辑特征和统计分布特征的保留程度。为满足这种特性,数据的原始值需要尽可能地被保留。
4)时效性。数据提供需要有一定的及时性,超过一定时间后脱敏数据可能就不再具有进一步分析挖掘的意义。因此,应尽量避免使用耗时的脱敏算法,比如加密算法。
5)可重现。即相同源数据在配置相同算法和参数的情况下,脱敏后的数据应保持一致,随机类的算法应避免使用。
6)可配置。主要是指可以灵活配置、组合脱敏算法,可以结合不同需求生成个性化的脱敏数据。
由于上述各因素需要付诸实际应用才有意义,脱敏算法与脱敏效果之间的关系只能作定性分析。决策树是一种简单而又被广泛使用的分类器,具有描述性,有助于人工分析,同时决策树只需一次构建,可反复使用[13]。对敏感级值和6个因素进行量化,以具有代表性的应用场景来构建选择脱敏算法所需的训练集,形成决策树。利用决策树可以高效地对脱敏数据进行算法推荐,辅助系统用户进行算法选择。新的脱敏应用发生后,其敏感级值和算法选择结果将加入训练集,逐步对决策树进行完善,从而提高决策树的鲁棒性。