本文由科学软件网整理发布
利用数据分析解决严峻的业务和研究挑战
IBMSPSS Statistics 是集成的系列产品,有助于应对整个分析流程,从规划和数据收集到分析、报告和部署。提供数十种完全集成的模块供您选择,您可以找到增加收入、超越竞争对手和改善决策所需的专业化的功能。
IBM SPSS Statistics各模块介绍
IBM SPSS Advanced Statistics
功能强大的建模技术,用于分析复杂的关系
IBM SPSS Advanced Statistics 提供单变量和多变量的建模技术,帮助用户在处理描述复杂关系的数据时,得到最准确的结论。通过频繁应用这些成熟的分析技术,可以从各学科(例如,医学研究、制造、制药和市场研究)使用的数据中获得更深入的洞察力。
SPSS Advanced Statistics 提供以下功能:
· 一般线性模型 (GLM) 和混合模型程序。
· 广义线性模型 (GENLIN),包括广泛使用的统计模型,例如针对正态分布数据的线性回归、针对二元数据的逻辑模型,以及针对计数数据的对数线性模型。
· 线性混合模型(也称为分层线性模型,HLM)扩展了 GLM 程序中使用的一般线性模型,使您能够分析具有相关性和非恒定可变性(non-constant variability)的数据。
· 广义估算方程 (GEE) 程序扩展了广义线性模型,适用于关联的纵向数据和聚类数据。
· 广义线性混合模型 (GLMM),用于分层数据和各种结果,包括序数值。
· 生存分析程序,用于检验生存期数据或持续时间数据。

线性混合模型的估算平均值
GLMM 提供估算的边际均值,用于说明预测变量的影响。

广义线性混合模型的模型摘要
GLMM 模型摘要展示了模型与数据的拟合程度。

广义线性混合模型可视化
GLMM 提供了模型的可视表示,您可以直观看到每个预测因素的强弱。在本示例中,promo 变量对销售影响最大。
IBM SPSS Bootstrapping
创建更可靠的模型并生成更准确的结果
IBM SPSS Bootstrapping 是一种确保分析模型可靠且能生成准确结果的有效方式。它可用于测试整个 SPSS Statistics 产品家族中分析模型和程序的稳定性,包括描述性统计信息、平均值、交叉表、相关、回归等。
SPSS Bootstrapping 支持您:
· 通过对原始样本的替代项进行重抽样,快速轻松地估算抽样分布特征。
· 为数据集合创建数以千计的可替换版本,以更准确地了解哪些数据最有可能存在于总体中。
· 减少离群值和异常值的影响,帮助确保模型的稳定性和可靠性。
· 估算总体参数的标准误和置信度区间,这些总体参数包括平均值、中值、比值、优势率、相关系数、回归系数等。
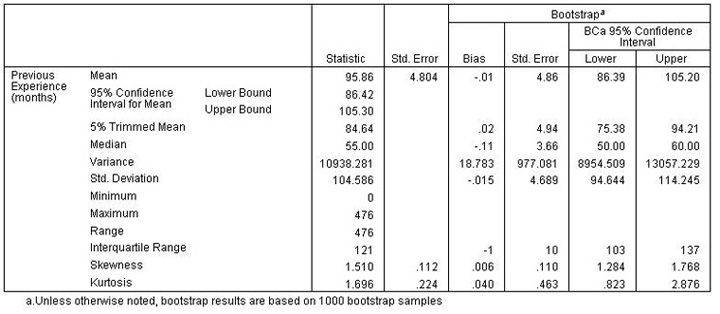
描述性表格
描述性表格提供了描述性的统计信息,以及这些统计信息的 bootstrap 置信区间。平均值的 bootstrap 置信区间 (86.39, 105.20) 与参数化的置信区间 (86.42, 105.30) 类似,表示“典型”员工大约具有 7 到 9 年的工作经验。但是,工作经验(月)呈偏态分布,因此平均值不能够很理想地代表当前的“典型”工资,这里使用中值会稍好一些。
IBM SPSS Categories
预测结果,揭示分类数据中的关系
IBM SPSS Categories 方便地直观呈现和探索数据中的关系,并根据您的发现预测结果。您可以使用先进的技术(例如,预测分析、统计学习、感知图和首选项缩放),了解消费者心目中认为与您的产品或品牌相关性最高的特征有哪些,并了解消费者对于您的产品与其他产品之间关联的认知。
SPSS Categories 包含先进的分析技术,用于帮助您:
· 更完整更轻松地分析和解释多变量数据及这些数据之间的关系。
· 通过对分类数据执行额外的统计操作,将定性变量转变为定量变量。
· 无论您调研的是何种类别类型,包括消费群、医疗诊断、政治党派或生物物种,都能以图形化方式显示底层关系。
IBM SPSS Complex Samples
分析复杂样本的统计数据并解释调查结果
IBM SPSS Complex Samples 帮助市场研究人员、民意调查人员和社会学家通过将样本设计整合到其调研分析中,提供更有效的统计推论。 SPSS Complex Samples 为您提供实施复杂样本设计(例如,分层抽样、整群抽样或多阶段抽样)所需的专门规划工具和统计信息。
· 将样本设计整合到调研分析中,以获得更准确的结果。
· 保留调查规划参数供将来使用,从而加快分析速度,提高效率。
· 管理复杂的调查数据以开展彻底的详细分析。
· 使用直观的界面和实用的向导,更快速地分析数据和解释调研结果。
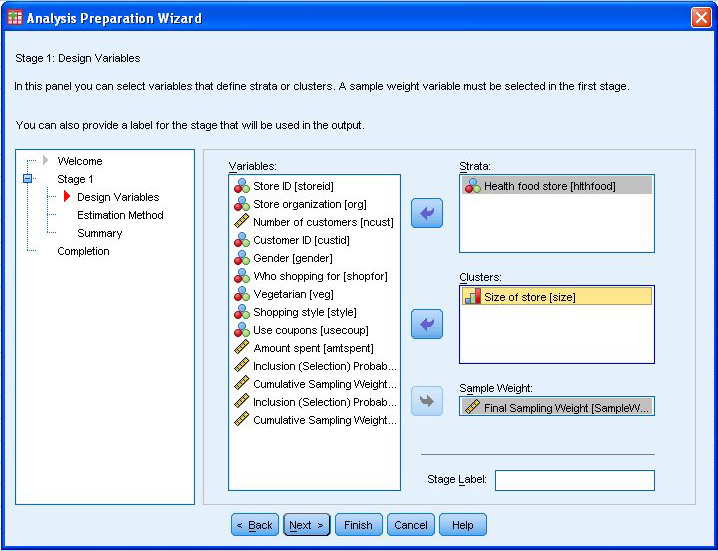
分析规划向导
要分析样本数据,请使用由“分析规划向导(Analysis Plan Wizard)”创建的分析设计,作为“复杂样本描述性统计数据(Complex Sample Deives)”或“复杂样本制表(Complex Sample Tabulate)”的输入。

通用线性模型
构建线性回归和方差分析模型,预测考虑样本设计的情况下的数字结果。该程序在估算方差时将样本设计考虑在内,抽样方法包括等概率抽样方法、PPS 抽样方法以及 WR 与 WOR 抽样方法。
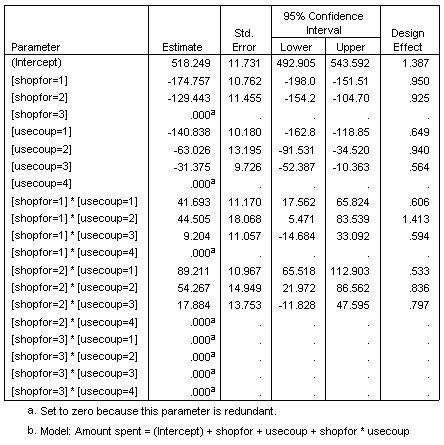
参数估算
参数估算显示每个预测变量对所花费金额造成的影响。截距项的值 518.249 说明,杂货连锁店可以预测,使用报纸以及有针对性的邮寄广告上优惠券的家庭平均花费为 518.25 美元。参数估算有助于量化每个模型项的影响,但是估算的边界均值表格也能轻松解释模型结果。
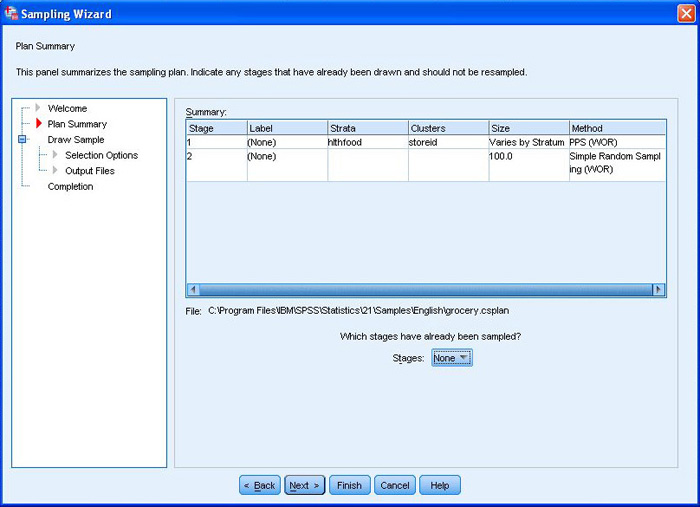
抽样规划向导
指定抽样框架以创建复杂样本设计,该设计由复杂样本附加模块中的伴随程序所使用。要对个例进行抽样,请使用由抽样规划向导所创建的样本设计,作为复杂样本选择程序的输入。
IBM SPSS Conjoint
了解和衡量购买决策
IBM SPSS Conjoint 帮助市场研究人员增加对消费者喜好的了解,以便更有效地设计、定价和营销成功产品。它支持研究人员对消费者决策过程进行建模,以便设计出包含对目标市场最重要的功能和属性的产品。
SPSS Conjoint 可帮助研究人员:
· 使用设计生成器 ORTHOPLAN 设计产品属性组合的正交阵列。
· 制作并打印卡片供调研受访者对备选产品进行挑选、排序或评级。
· 使用结合分析(conjoint analysis,一种专门定制的回归版本)分析研究数据。

正交设计
正交设计的输出结果是每个剖面(profile)具有对应的一行,而各种因素显示为列。脚注可使实验人员(而非其他测试参与者)了解哪些个例(如果有)为保留个例。

该表指出,在使用三个不同选择概率模型的情况下,选择每个模拟个案作为首选的预测概率。
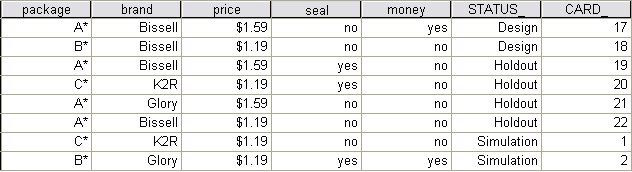
模拟个案
联合分析的真正威力在于,能够对未经主体评级的产品概要信息预测首选项。这些即所说的模拟个案。模拟个案、来自正交设计的概要信息(profile)以及检验用的概要信息(profile)都包含在计划中。
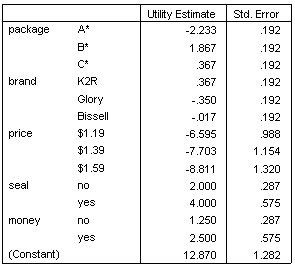
实用程序评分
该表显示了实用程序(效用值)评分及其每个因子级别的标准误。实用程序值越高,表示首选项越好。
IBM SPSS Custom Tables
分析数据并在更短的时间内创建定制表
使用 IBM SPSS Custom Tables 能轻松针对不同受众以不同样式总结 IBM SPSS Statistics 数据。它结合了多种分析功能,您可以构建人们非常容易阅读和明白的表,帮助您从数据中了解更多信息。
该软件对于那些定期创建和更新报告的用户很实用,尤其是那些从事调查或市场研究、社会科学、数据库或直销、院校研究工作的人。
SPSS Custom Tables 帮助您:
· 执行深入的分析,以便更好地了解自己的数据并为决策者提供改进的报告。
· 在构建表时进行预览,确保在更短时间内创建精炼、准确的报告。
· 定制表的布局和外观,以清晰准确地表达结果。
· 通过提供人们无需进一步处理即可作为行动依据的信息,保证结果的易用性。
拖放式表构建方法
SPSS Custom Tables 直观的图形用户界面使您不再需要靠猜测来构建表。其拖放功能和预览窗格使您可在单击“确定”之前,对表格的内容和外观进行检查。
图形用户界面
直观的界面可帮助您轻松构建复杂的表,包括嵌套和堆积表。
可定制的表格式
SPSS Custom Tables 提供一系列选项,帮助您控制表格的外观,包括添加标题和文字说明、指定列宽以及排列和隐藏类别的功能。
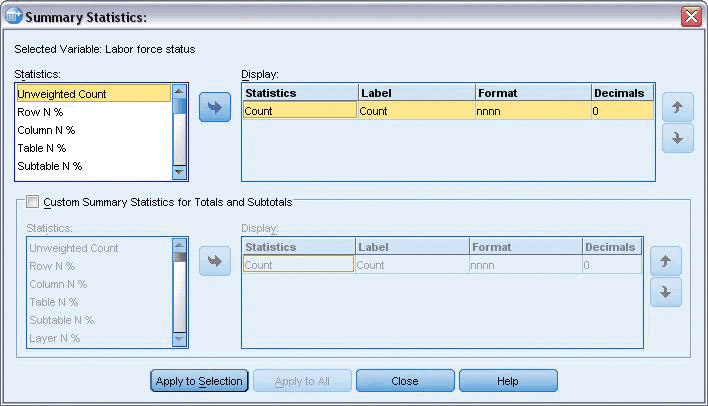
多个汇总统计
将各种统计信息添加至各个表单元格(从针对分类变量的简单计数到离差测定),并按照使用的任何汇总统计信息对类别进行排序。
IBM SPSS Data Preparation
改进数据准备过程,生成更准确的结果
IBM SPSS Data Preparation 执行先进技术,以简化分析过程的数据准备阶段,从而更快速、更准确地提供数据分析结果。分析人员可以从完全自动化的数据准备过程中进行选择,从而最快地获得结果,或者从其他几种方法中进行选择来准备更具有挑战性的数据集。
利用该软件,您可以轻松发现可疑或无效的个例、变量和数据值。验证数据工具帮助您发现活动数据集中可疑和无效的个例、变量及数据值。
SPSS Data Preparation 有助于:
·