0 引言
在大数据和云计算热潮中,内存数据库市场的复合年增长率为43%(全球研究公司Markets&Markets预测),从2013年的22.1亿美元跃升至2018年的132.3亿美元。内存计算最重要的驱动力来自内存数据库允许对“实时”事务数据的实时分析和实时的情境意识,而不是对“过时数据”进行事后分析。
更多公司正在采用或者计划采用实时分析,这样做的驱动是来自增加业务流程的速度和准确性的压力,特别在数字业务和物联网方面。随着数据规模越来越大,从万亿字节(TB)到千万亿字节(PB)级;一部智能手机每日可产生30 MB左右的数据量,而一座高自动化的工业4.0的工厂,一天产生的数据可以超过一个PB。大数据所带来的大规模及需要实时处理等特点与传统的以计算为中心的模式产生巨大矛盾,使得传统计算模型难以适应当今大数据环境下的数据处理。数据处理从以计算为中心转变成以数据为中心,通过使用传统的内存—磁盘访问模式处理大数据存在I/O瓶颈,处理的速度问题愈发突出,且时效性难以保证,现有的方案都只能一定程度上缓解这个瓶颈。每家大型公司每分钟都会做出数千次实时决策,企业的需求使得内存计算技术成为目前广受关注的技术。本文研究了从海量数据中识别出哪些数据是真正的热点数据,然后根据数据的热度,分别将数据放入列式内存、行式内存、闪存和硬盘,进行存储的智能分级管理,进而通过内存计算技术支持企业级实时计算需求[1]。
1 数据库内存计算
内存计算的概念最早被提出是在20世纪90年代,当时硬件发展有限,没有得到进一步深入研究。直至2010年以后,随着内存价格大幅下降,内存容量增长,将大量数据存入专用服务器内存得以实
现[2]。而真正在企业级核心系统中运用最成功的方式是Database In-Memory,即内存数据库。关系型数据库管理系统(Relational Database Management System,RDBMS)作为企业核心数据的管理系统,如果具备内存计算能力,可以直接使企业的业务系统获得实时计算的能力。这个领域也涌现出众多的技术方案,其中Oracle的Oracle Database In-Memory选件是应用较为成功的技术,可以支持用户在不修改原有程序的情况下,快速实现内存计算,透明地加速分析查询[3],从而大幅度提升计算性能,实现实时业务决策。
Oracle Database In-Memory技术要点是同时以行、列2种形式缓存数据[4]。Oracle数据库传统上以行格式存储数据。在一个行格式数据库中,数据在数据库中以行式存储,每行数据包含多列,每列代表关于该记录的不同属性。行格式是联机事物处理系统(Online Transaction Processing,OLTP)的理想选择,给定记录的所有属性顺序保存在一起,可以快速访问记录中的所有列。列格式数据库将记录的每个属性以列的形式存储,列格式是联机分析系统(On-Line AnalysisProcessing,OLAP)的理想选择,因为它只允许更快的数据检索[5]。
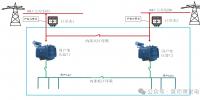
Oracle Database In-Memory支持在内存中同时缓存行、列2种格式,这种双格式的内存计算架构不会增加太多的内存开销,通过数据压缩和内存存储优化,增加列式缓存后内存开销只增大约20%[6]。相对于性能方面的提升,内存方面为了获得最佳性能而付出的代价是很小的。双格式的内存计算架构如
 图1 双格式的内存计算架构Fig.1 Dual-format Database In-Memory architecture
图1 双格式的内存计算架构Fig.1 Dual-format Database In-Memory architecture
Database In-Memory做到了行列2种格式的共存,并且实现了2种格式数据的事物级一致性[7],使得OLAP业务通过内存计算提升性能,支持实时分析,同时还可以较少分析类索引数量,使得OLTP类业务性能也有提升,充分体现了内存计算的优势。
2 数据热图
信息生命周期管理(Information Lifecycle Management,ILM)是根据企业当前的业务和性能需求将数据存储在不同的存储和压缩层中,这种方法提供了优化存储以节省成本和最大性能的可能性。
在Oracle Database 12c中包含2个ILM功能。一是数据热图(Heat Map),通过热图可以聚合大量数据,使用直观的方式表现数据的温度,自动跟踪在行和段级别的修改和查询时间戳,提供有关如何访问数据的详细信息[8-9]。二是自动数据优化(Automatic Data Optimization,ADO),根据热图收集的信息,利用用户定义的策略自动移动和压缩数据。Heat Map和ADO可以利用Oracle数据库压缩和分区技术降低管理大量数据的成本,同时还能提高应用程序和数据库性能。
数据热图可以细粒度地跟踪数据使用情况,跟踪行和段级别的表/分区使用信息,以及在行级别跟踪数据修改时间、全表扫描时间,聚合到块级别,并在段级跟踪索引查找时间。热图提供了数据使用情况的详细视图,以及访问模式如何随时间变化的信息。数据热图示例如
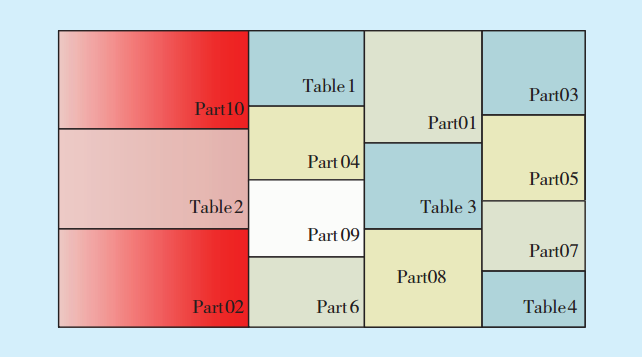 图2 数据热图示例Fig.2 Heat map data example
图2 数据热图示例Fig.2 Heat map data example
红色说明数据最热,黄色可以叫做温数据。如果为蓝色,则这类数据可以安全地移动到低级存储设备(例如迁移到性能较低的廉价存储),这种类型的数据也被称为“过期数据”或“归档数据”。
企业级系统由于数据量庞大,如果简单的将所有数据按照相同服务水平管理,如采用同一级别的存储保存所有数据,则无法控制系统的成本或保证应用的性能。最关键或经常访问的数据需要最佳的性能和可用性,但为所有数据提供这种最佳的访问质量的存储方案是昂贵的,低效的,并且在结构上通常是不可能做到的。因此需要实施数据存储分层的分级管理。
通过存储分层,可以将数据部署在不同的存储层上,从而将较少访问(较冷)的数据迁移出最昂贵、最快的存储。较冷的数据仍然在线可用,但速度较慢,这是由于较冷数据的很少访问对整体应用程序性能的影响最小。活跃程度更低的数据也可以在存储中被压缩到更高的水平。数据生命周期管理常用技术是存储分层与数据压缩。
数据存储分级主要是内存、闪存、普通固态硬盘(Solid-State Disk,SSD)、机械磁盘与离线存储的磁带。SSD存储设备与传递机械硬盘不同,SSD可以并行处理多个随机存取请求,不会产生单个I/O请求降级导致的等待时间[10-11],组合多种介质和数据压缩可以构造出更多的层次。
3 自动化协同架构
内存计算、数据热图和数据分级存储3种技术各有侧重。其中数据热图与数据分级存储主要应用于数据生命周期管理,内存计算则用于实时分析。采用热图结合分级策略,将最需要的数据放入内存中,实现3种机制的自动化协同,达到在最低内存成本上的最大性能收益。内存计算、数据热图和数据分级存储自动化调度模型如
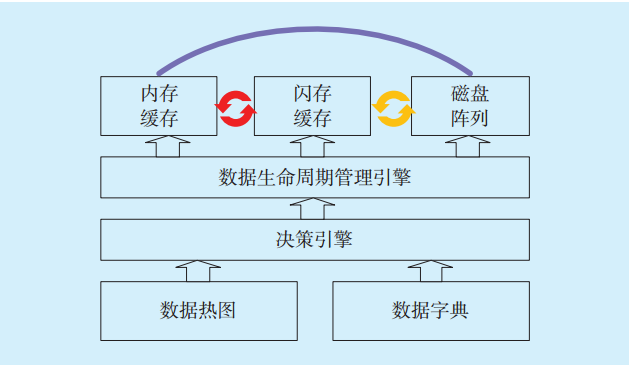 图3 自动化调度模型Fig.3 Automated scheduling model
图3 自动化调度模型Fig.3 Automated scheduling model
3.1 决策引擎
决策引擎是系统的关键部分,旨在优化数据库中的数据分析类操作,基于知识库分析数据库中存在的分析处理工作负载,推荐需要加载或卸载出内存的数据,并提供决策实施后估计收益。
决策引擎主要有3部分组成:策略库、热图、模式匹配模块。决策引擎工作模式如
 图4 决策引擎工作模式Fig.4 Decision engine working mode
图4 决策引擎工作模式Fig.4 Decision engine working mode
决策引擎基于数据热图分析数据的温度,根据对数据库对象的SQL操作模式、活动会话历史(Active Session History,ASH)的跟踪数据,结合使用其他统计信息来分析数据的分区和分布情况。
预置的策略主要逻辑是消除用户I / O等待、集群传输等待和缓冲区高速缓存锁等待等数据库等待事件,可以分析某些查询处理的特点,推荐特定的压缩类型。预置的策略是基于业务模式、数据库建模和数据库运维的经验人工创建的。根据策略引擎的决策可以自动或人工确认后通过DBMS管理包进行对象加载/卸载操作。
策略库中预定义了一些数据优化的规则。如:某表或分区累计30天没有写操作,没有频繁读操作,则推荐进行列式压缩;某表或分区累计30天有少量写操作,多次全表扫描,则推荐加载到列式内存缓存区域;某表为时间分区表,按天分区。按业务规则,每天凌晨完成入库,当日日间频繁查询,人工定义每日加入列式内存缓存区域,7天后卸载出内存。
策略库随着信息不断收集入库,逐渐丰富,决策越来越准确。策略库结合数据热图中的热点数据进行模式匹配,模式匹配将从热图中找到的热点数据按照策略库中提供的规则逐条过滤,发现符合条件的热点数据,则按照策略向数据生命周期管理引擎发起操作请求。
决策引擎底层数据库建模如
 图5 决策引擎数据库建模Fig.5 Decision engine database modeling
图5 决策引擎数据库建模Fig.5 Decision engine database modeling
决策引擎的决策过程基于数据库热图的几个基础视图,如:v$heat_map_segment,以及本身策略库的基础表T_RULE和记录决策引擎制定出的数据生命周期管理的方案T_OBJPOLICY,还有引擎运算使用的数据库和操作系统各种状态指标的采集表。
3.2 数据生命周期管理引擎
Oracle Database12cR1中推出了Automatic Data Op