本文介绍基于内容的推荐算法(Content-based Recommendation)。
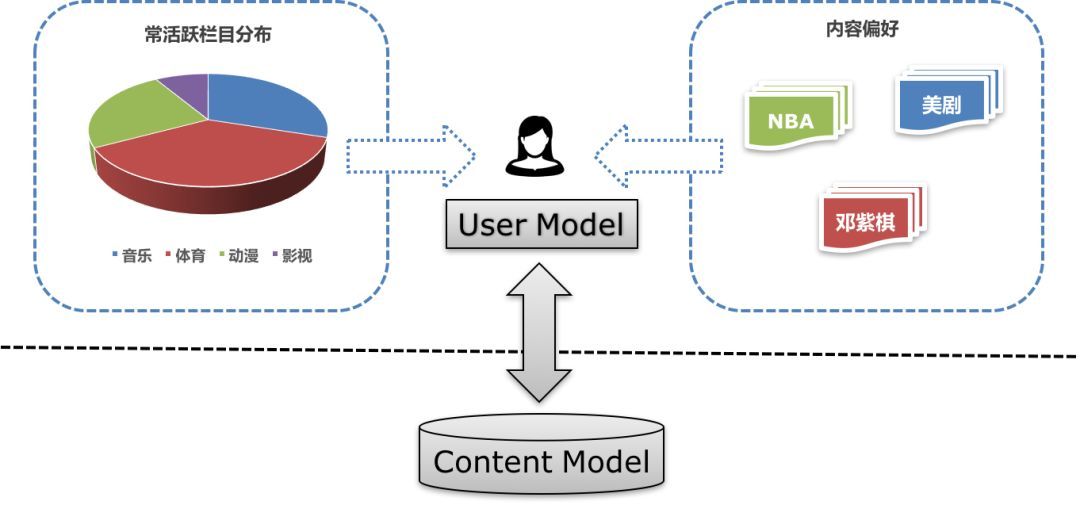
基于内容的推荐算法(以下简称“内容推荐算法”)只有一个关键点——标签(tag)。推荐算法将产品分解为一系列标签,并根据用户对产品的行为(例如,购买、浏览)将用户也描述为一系列标签。
内容推荐算法的原理:
1.将产品分解为一系列标签。例如,一个手机产品的标签可以包括品牌、价格、产地、颜色、款式等。如果是自营b2c电商,一般可以在产品入库时手动打标签。
2. 基于用户行为(浏览、购买、收藏)计算每个用户的产品兴趣标签。例如,用户购买了一个产品,则将该产品的所有标签赋值给该用户,每个标签打分为1;用户浏览了一个产品,则将该产品的所有标签赋值给该用户,每个标签打分为0.5。计算复杂度为:已有产品数量*用户量。该过程为离线计算。
3. 针对所有新产品,分别计算每个用户的产品标签与每个新产品的相似度(基于cosine similarity)。计算复杂度为:新产品数量*用户量。该过程为在线计算。
从可行性角度,一个应用场景是否适合用内容推荐算法取决于:
1. 是否可以持续为产品打标签。
2. 标签是否可以覆盖产品的核心属性?例如,手机产品的标签一般可以覆盖消费者购物的核心决策因素,但是女装一般比较难(视觉效果很难被打标)。
内容推荐算法的优势:
1. 推荐结果可理解:不仅每个用户的核心兴趣点可以被标签化(便于理解每个用户的兴趣),并且可以在每一个推荐结果的展示中现实标签,便于消费者理解推荐结果(如下图红框)。
2. 推荐结果稳定性强:对于用户行为不丰富的产品类型(例如,金融产品),协同过滤很难找到同兴趣用户群或关联产品,在相似度计算中稀疏度太高。然而,内容推荐主要使用标签,标签对用户兴趣捕捉稳定性要远远高于单个产品。
3. 便于人机协作:用户可以勾选或者关注推荐标签,从而通过自己的操作来发现自己的个性化需求。
内容推荐算法的劣势:
1. 不适合发现惊喜:如果一个产品不易于被标签穷举或描述产品的标签还没出现,则该产品很难被准确推荐。
2. 在线应用计算复杂度较高:需要基于每个用户来计算相似产品。