- 过拟合怎么理解?如何解决?
- 正则化怎么理解?如何使用?
在机器学习中有时候会出现过拟合,为了解决过拟合问题,通常有两种办法,第一是减少样本的特征(即维度),第二就是我们这里要说的“正则化”(又称为“惩罚”,penalty)。
从多项式变换和线性回归说起
在非线性变换小节中,我们有讨论Q次多项式变换的定义和其包含关系,这里如果是10次多项式变换,那么系数的个数是11个,而2次多项式的系数个数是3。从中我们可以看出,所有的2次多项式其实是10次多项式加上一些限制,即w3=w4=...=w10=0。

基于上面的讨论,我们希望能将二次多项式表示成十次多项式再加上一些约束条件,这一步的目的是希望能拓宽一下视野,在推导后面的问题的时候能容易一些。
这个过程,我们首先要将二次多项式的系数w拓展到11维空间,加上w3=w4=...=w10=0这个条件得到假设集合H2;然后为了进一步化简,我们可以将这个条件设置的宽松一点,即任意的8个wi为0,只要其中有三个系数不为0就行,得到一组新的假设空间H2',但这个问题的求解是一个NP-hard的问题,还需要我们修正一下;最后,我们还需要将这个约束条件进一步修正一下得到假设集合H(C),给系数的平方的加和指定一个上限,这个假设集合H(C)和H2'是有重合部分的,但不相等。
最后,我们把H(C)所代表的假设集合称为正则化的假设集合。
下图表示了这个约束条件的变化:

正则化的回归问题的矩阵形式
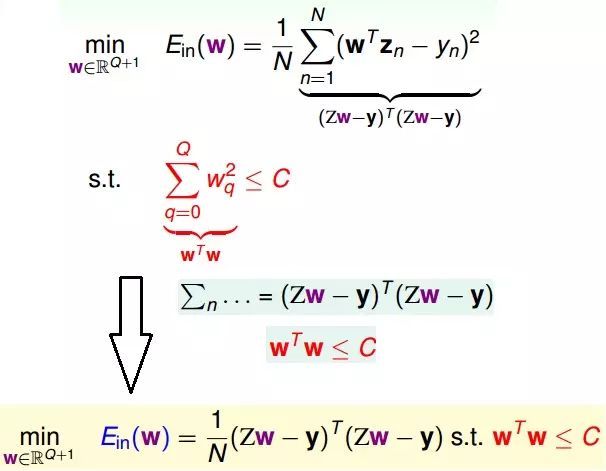
由上图所示,我们现在要求解的是在一定约束条件下求解最佳化问题,求解这个问题可以用下面的图形来描述。
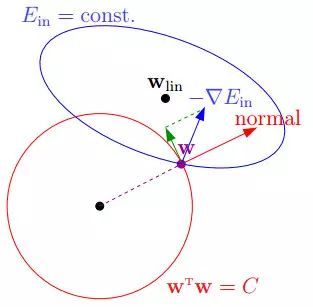
本来要求解Ein的梯度,相当于在一个椭圆蓝色圈中求解梯度为零的点,而下面这个图表示,系数w在半径是根号C的红色球里面(w需要满足的约束条件),求解蓝色区域使得梯度最小的点。
那么,最优解发生在梯度的反方向和w的法向量是平行的,即梯度在限制条件下不能再减小。我们可以用拉格朗日乘数的方法来求解这个w。


Ridge Regression
Ridge Regression是利用线性回归的矩阵形式来求解方程,得到最佳解。

Augmented Error
我们要求解这个梯度加上w等于0的问题,等同于求解最小的Augmented Error,其中wTw这项被称为regularizer(正则项)。我们通过求解Augmented Error,Eaug(w)来得到回归的系数Wreg。这其实就是说,如果没有正则项的时候(λ=0),我们是求解最小的Ein问题,而现在有了一个正则项(λ>0),那么就是求解最小的Eaug的问题了。

不同的λ造成的结果
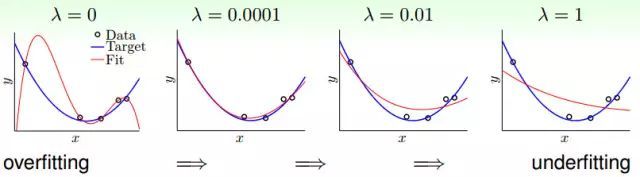
从上图可以看出,当λ=0的时候就会发生过拟合的问题,当λ很小时(λ=0.0001),结果很接近理想的情况,如果λ很大(λ=1),会发生欠拟合的现象。所以加一点正则化(λ很小)就可以做到效果很好。
正则化和VC理论
我们要解一个受限的训练误差Ein的问题,我们将这个问题简化成Augmented Error的问题来求解最小的Eaug。
原始的问题对应的是VC的保证是Eout要比Ein加上复杂度的惩罚项(penalty of complexity)要小。而求解Eaug是间接地做到VC Bound,并没有真正的限制在H(C)中。
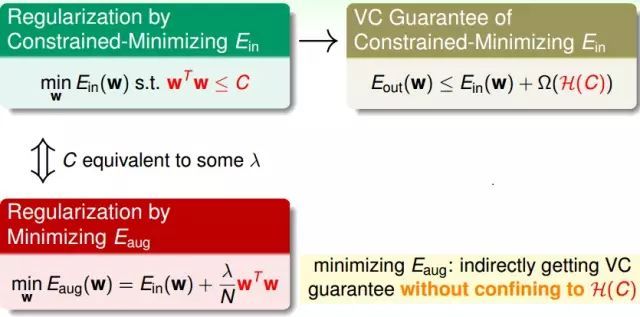
wTw可以看成是一个假设的复杂度,而VC Bound的Ω(H)代表的是整个假设集合有多么的复杂(或者说有多少种选择)。
这两个问题都好像是计算一个问题的复杂度,我们该怎么联系着两种复杂度的表示方式呢?其理解是,一个单独的很复杂的多项式可以看做在一类很复杂的假设集合中,所以Eaug可以看做是Eout的一个代理人(proxy),这其实是我们运用一个比原来的Ein更好一点点代理人Eaug来贴近好的Eout。

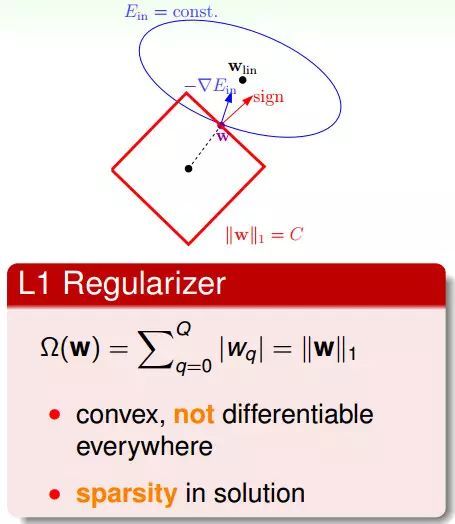
一般性的正则项 L1 Regularizer
L1 Regularizer是用w的一范数来算,该形式是凸函数,但不是处处可微分的,所以它的最佳化问题会相对难解一些。
L1 Regularizer的最佳解常常出现在顶点上(顶点上的w只有很少的元素是非零的,所以也被称为稀疏解sparse solution),这样在计算过程中会比较快。
L2 Regularizer
L2 Regularizer是凸函数,平滑可微分,所以其最佳化问题是好求解的。

最优的λ
噪声越多,λ应该越大。由于噪声是未知的,所以做选择很重要,我将在下一小节中继续接受有关参数λ选择的问题。
总结
过拟合表现在训练数据上的误差非常小,而在测试数据上误差反而增大。其原因一般是模型过于复杂,过分得去拟合数据的噪声和异常点。正则化则是对模型参数添加先验,使得模型复杂度较小,对于噪声以及outliers的输入扰动相对较小。
正则化符合奥卡姆剃刀原理,在所有可能选择的模型,能够很好的解释已知数据并且十分简单才是最好的模型,也就是应该选择的模型。从贝叶斯估计的角度看,正则化项对应于模型的先验概率,可以假设复杂的模型有较小的先验概率,简单的模型有较大的先验概率。
参考资料
机器学习中的范数规则化之(一)L0、L1与L2范数
http://blog.csdn.net/zouxy09/article/details/24971995
机器学习中的范数规则化之(二)核范数与规则项参数选择
http://blog.csdn.net/zouxy09/article/details/24972869
作者Jason Ding
http://blog.csdn.net/jasonding1354/article/details/44006935#comments