3 引发技术变革的电力大数据
3.1 数据规模大,数据处理时效性要求高——传统技术手段不能经济地满足业务性能需求
3.1.4实际案例:基于大数据的短期负荷预测
4.具体案例
为了体现该方案在负荷预测过程中呈现的良好效果,将该部分结合一个实际算例来做出分析。目标电网为国内配备用户用电信息采集系统的某市级电网,该市级电网的用户数为120万,用电信息采集频率为每15分钟一次。在具体案例的介绍中,主要分为两大部分:第一部分主要介绍该方案中数据挖掘算法在用户用电行为分析及预测模型上的应用;第二部分则主要介绍该方案如何移植到大数据平台上完成数据的存储和计算。
第一部分:基于数据挖掘算法在用户用电行为分析及预测模型;
在形成与预测日曲线类型、负荷水平以及影响因素相近的相似日时,需要对大量的历史数据集进行有效的归类和分析。由于原始数据集的簇结构以及与影响因素的耦合关系均未知,因此需要结合数据挖掘算法予以解决。
☆凝聚层次聚类算法对历史样本分类
对于每一个用户来说,其历史负荷曲线因为天气、节假日等影响会产生走势各异的不同曲线类型对其进行有效的聚类,可以帮助缩小待预测日的相似日数据样本集规。凝聚层次聚类算法在这里被采用来获取良好的预测结果,层次聚类算法是一种自下而上的归并算法,通过计算每个样本之问的欧式距离.来实现最终归类的效果。
计算任意两个历史负荷样本的欧式距离;
设n维样本空间s中任意两个数据序列X、Y分別为:X={x1、x2、x3…xn},Y={y1、y2、y3、yn},其欧式距离为:
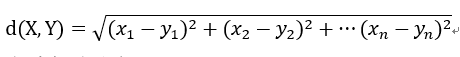
设定阈值合并相近的类。
设定曲线间的距离阈值为d,在S中有N条负荷曲线序列{L1、L2、L3…Ln},任意取出曲线Ln并计算与其他曲线间的欧式距离,合并最近的两个簇,直到达到预定的分类目标即可停止。我们在第一部分数据挖掘算法的描述中都采用目标电网中的一个用户做出分析,该用户记为用户1.对用户1的2012年365天的数据聚类结果如图—3所示。
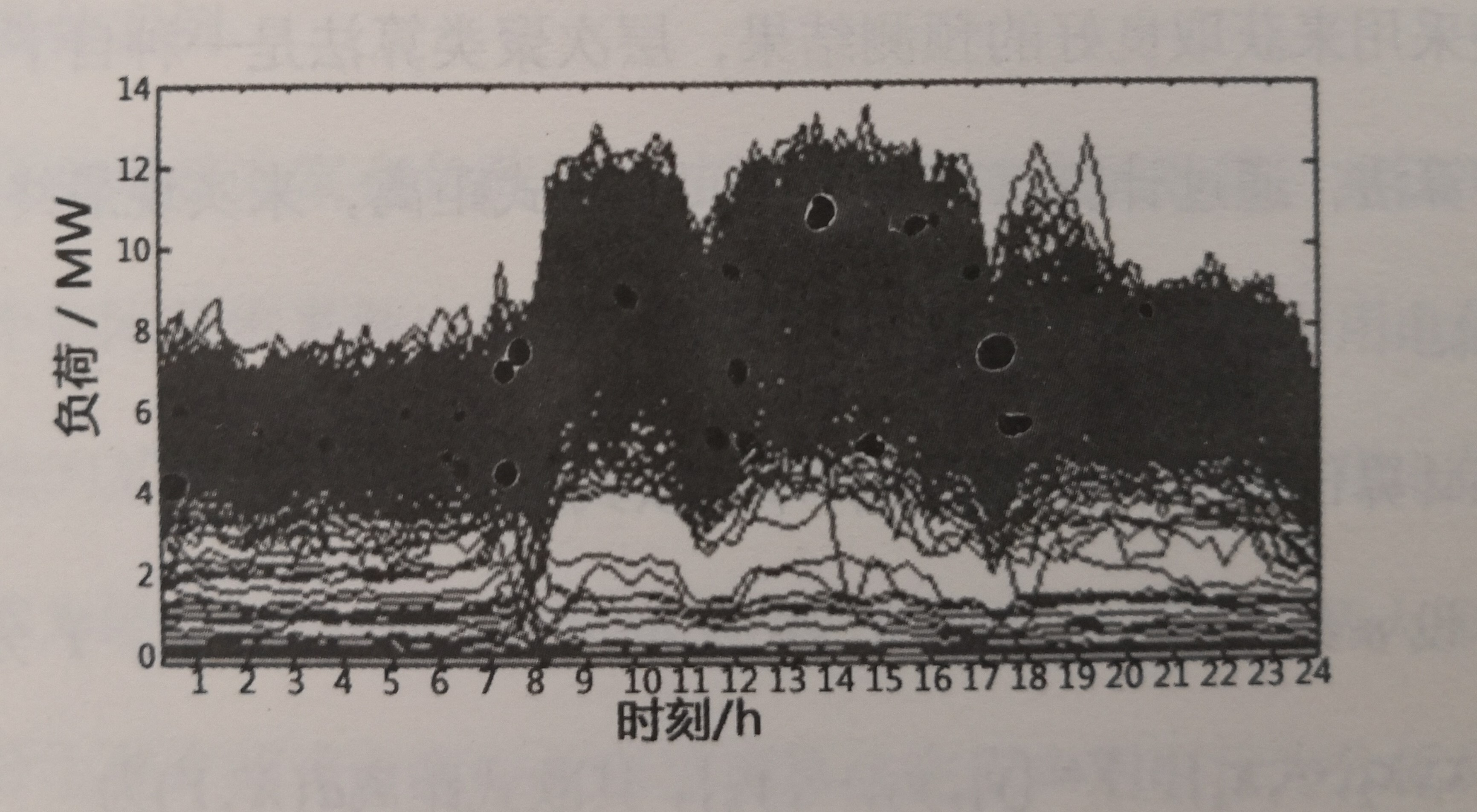
图3-3 2012年1月1日到2012年12月31日期间的用户1日负荷曲线
在经过凝聚层次聚类算法的处理分析后,图3-3中用户I全年的负荷数据可以归类为图3-4中的六类负荷曲线。可以看出六类负荷曲线在幅值大小及曲线走势上均存在较大的差异、同时在表3-2中,可以看出类3和类4主要为工作日负荷,类2主要为周末负荷,进一步分析其节假属性,发现第六类中含有大量的节假日如国庆节等的负荷,而第一类中则主要为节假日前一天的负荷、分析表明,该算法成功完成了分类的任务。

表3-2每一类中各类型日的数量
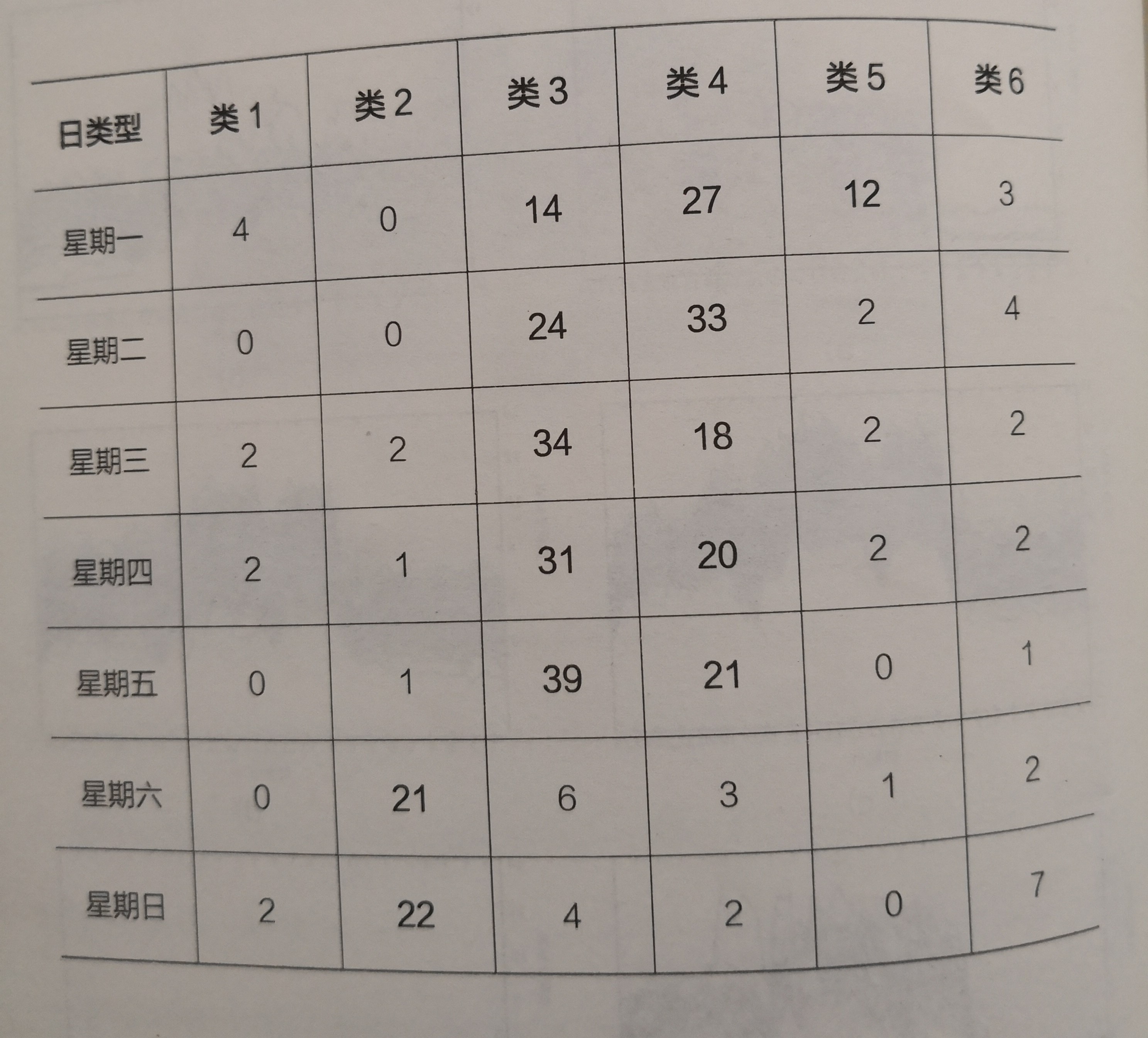
图3-4用户1的六类负荷曲线图
☆灰色关联分析选取关键影响因素
通过对用户1的历史负荷数据及历史天气数据进行灰色关联分析,可以得出影响用户1负荷变化规律的关键影响因素,有利于缩减样本集的数据维度,进一步提高准确度。对用户I的灰色关联度,计算结果见表3-3
表3-3
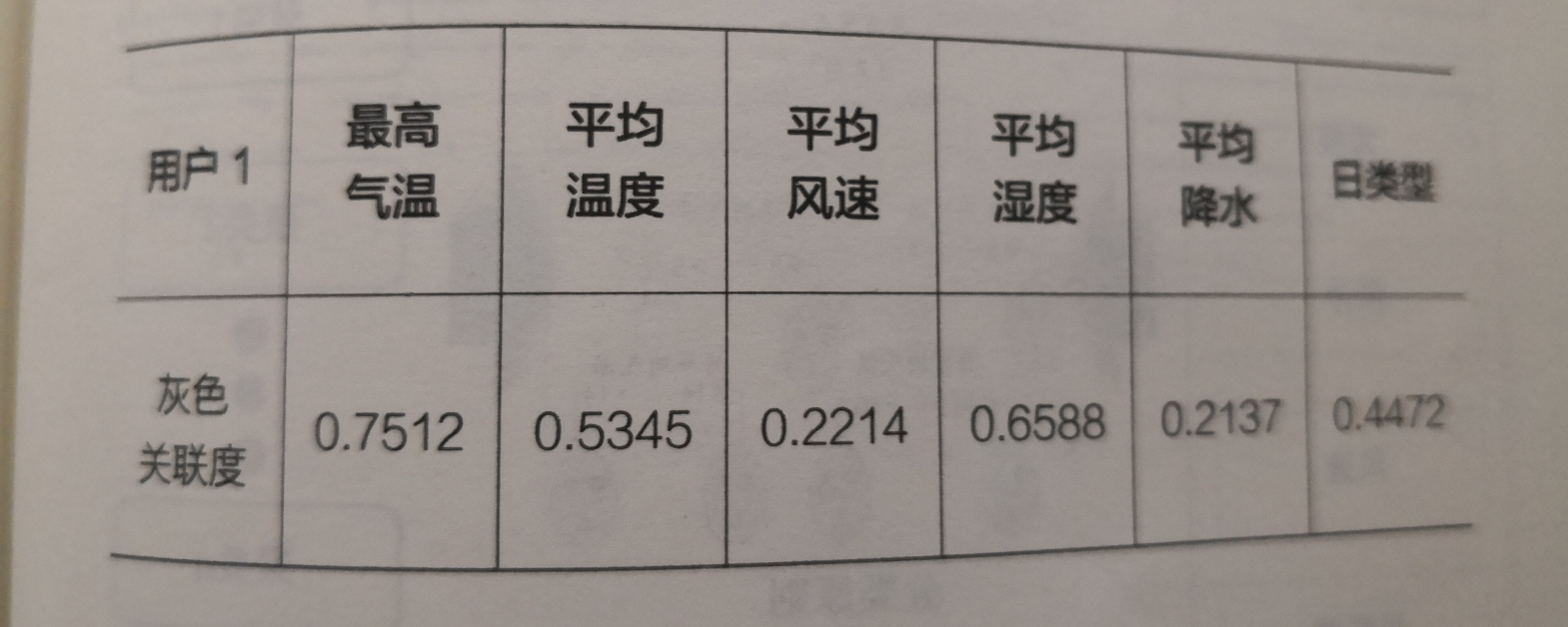
其中,可以看出最高气温、平均气温、日类型、平均湿度对负荷变化趋势的影响较大.为关键影响因素,在后续的分析中主要关注这几项影响囡素值。
☆CART决策树建立分类规则
这一步的计算结果需要在前两步的计算结果上完成。CART决策树算法根据信息增益度将样本按其若干影响属性値不断划分,最后归入指定的类。而用CART决策树来建立分类规则的思想如图3-5所示。
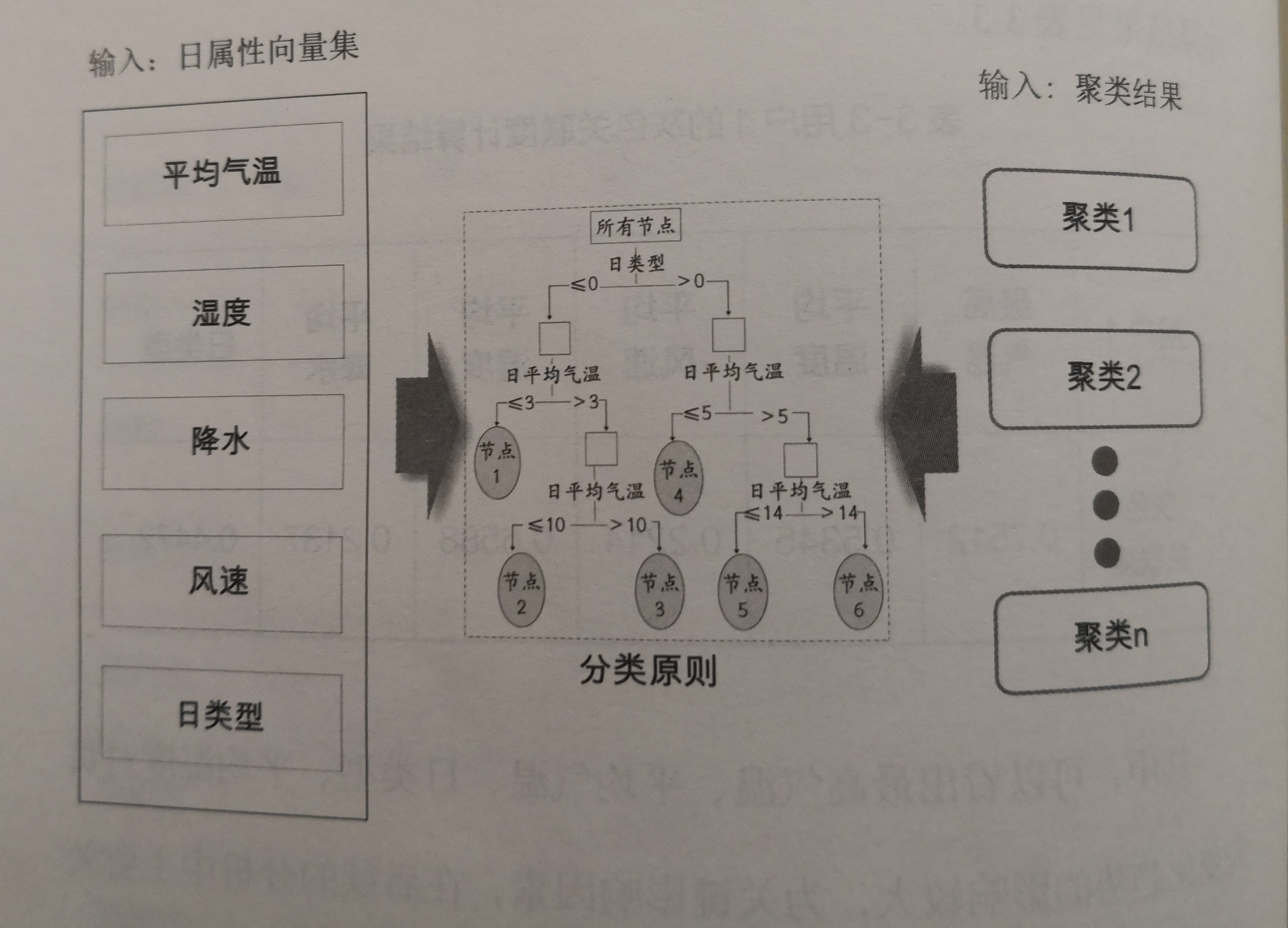
图3-5分类规则建立图
中间为决策树的箅法模型、左侧输入为日属性向量集,即2012年每一天对应的负荷影响因素数据集合。右侧输入为在层次聚类分析后得到的若干个类别。通过CART算法对用户1的数据进行若干次分裂,即可得到如图3-6所示的分类规则。

图3-6用户1决策树分类规则图
根据决策树算法对用户1的负荷曲线进行分析,得到图3-6所示的决策图。该树也是久特变负荷曲线分类规则.同时也表征了负荷聚类结果与关键。影响因素值的定量关系。举例如下:
2UI3年4月29日影响负荷的关键因素值如下表。

表3-4某日影响负荷的关键因素
由图3-6中黑色实线所示,该日被最终归入了第二类。而由聚类分析得出的第二类负荷在曲线特征上极其相似,这样就给出了负荷的分类规則。
☆找到待预测的同类型日数据集
我们已知了待预测日的相关因素数据,在图3-6所示的分类规则中可以将待预测日分到与之对应的类中,结果见表3-5
表3-5

☆针对每一类训练対应的支持向量机模型
支持向量机因其对非线性数据集较好的数据拟合能力而受到众多研究学者的青睐,本书采用支持向量机算法完成最终的负荷预测工作。支持向量机有几个关键参数会对最终的预测结果产生较大的影响,通过遗传算法对六类历史数据集分别进行寻优和计算,可以得到最为匹配的参数组合,详见表3-6
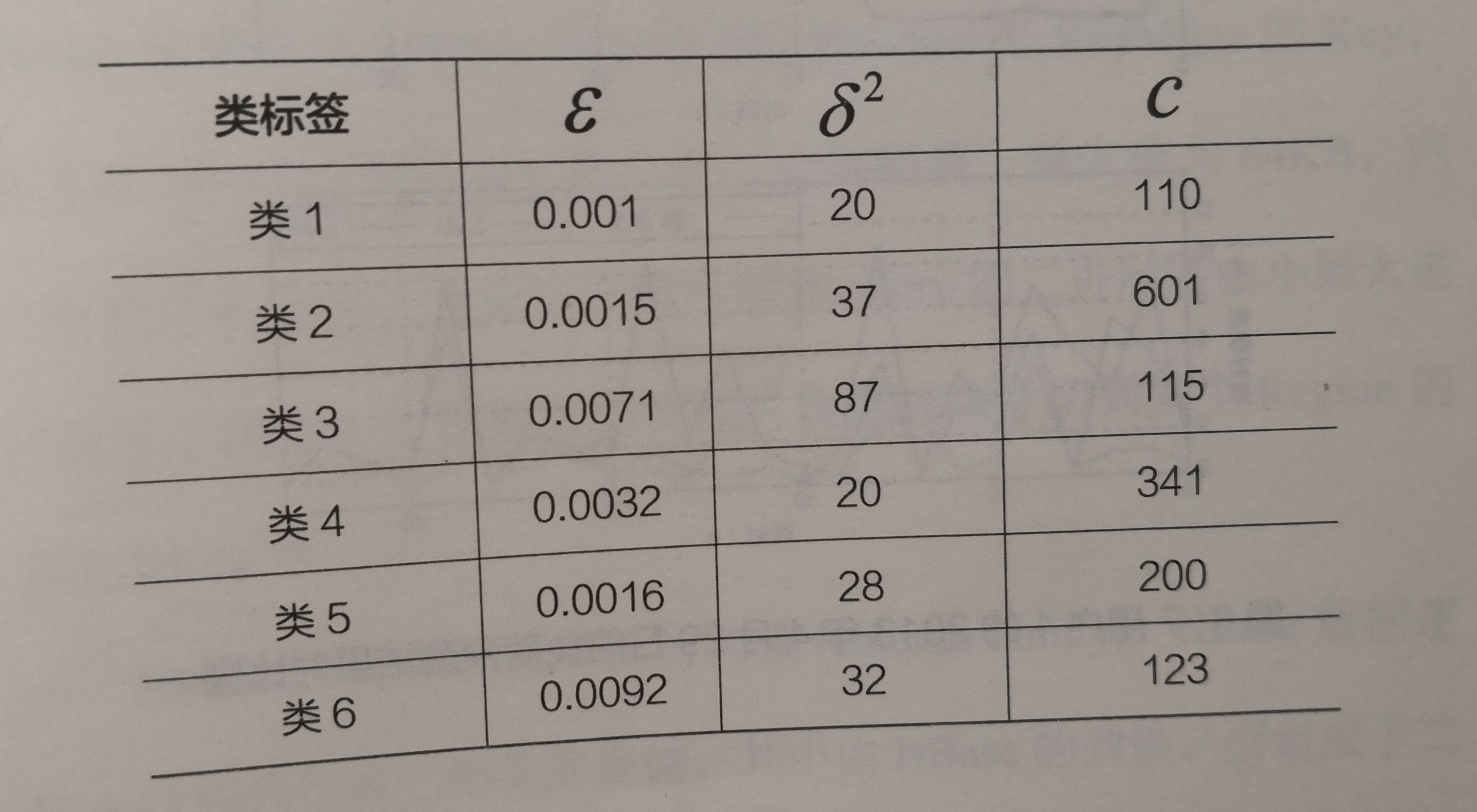
表3-6六类历史数据集的最优支持向量机参数组合
☆对用户1的预测结果如图3-7所示。
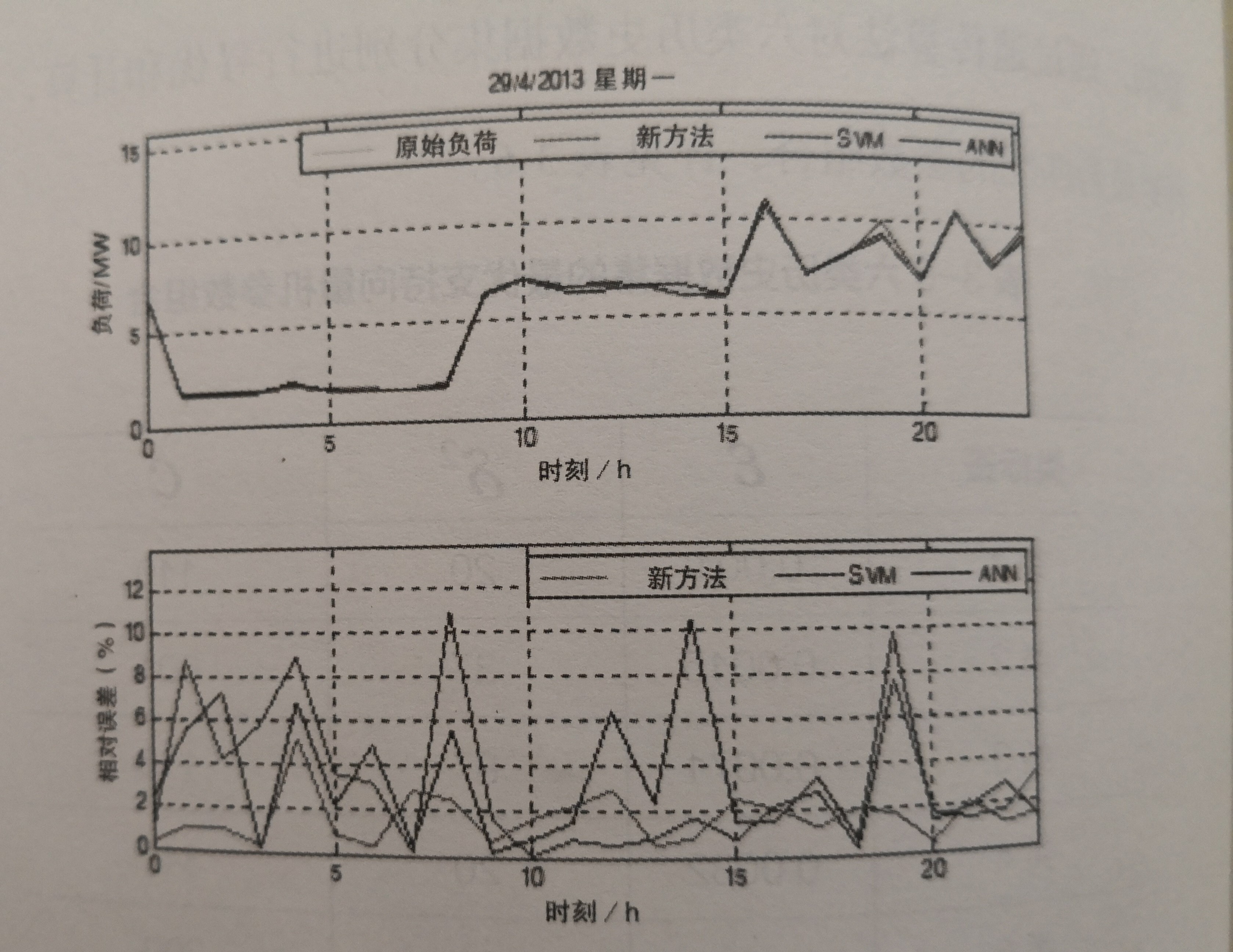
图3-7用户1的2013年4月29日的负荷预测结果对比圏
第二部分:在Hadoop大数据平台上完成系统负荷预测
由于上述案例仅针对120万用户中的用户1做了预测,而为了得到系统总负荷,则需要对每个用户执行上述操作,这个过程我们在Hadoop平台上给以实现。整个技术框架分为数据存储、数据管理,数据计算三个部分。
☆数据存储
在Hadoop的底层数据层中,分布式文件系统HDFS负责用户负荷及影响因素的分布式存储。
☆数据管理
HBase在分布式文件系统基础上,对底层的数据进行数据管理。HBase是采用KeyValue的列存储,Rowkey是KeyValue的Key,表示唯一一行。Rowkey是一段二进制码流,最大值为64KB,内容由用户自定义。数据的加载根据Rowkey的二进制序由小到大进行排序。HBase根据数据的规模将数据自动分切到多个Region的多个HFile中。
HBase的基本存储单元为列簇(columnfamily)。HBase数据選辑由行和列组成二维矩阵存储。其中由HBase列簇、列组成了一维矩阵中的一维,由Rowkey组成了另一维,每-个非空的行列节点称为一个Cell,Cell是HBase最小的逻辑存储单元。
图3-8为负荷数据的存储结构图,键值(key)代表的是对应时间点,从0点到23点45分,一天共96个点。图3-9中Value值为对应时间点的负荷值。UserId为用户的编号,而data则表示是该用户对应的某一天数据。
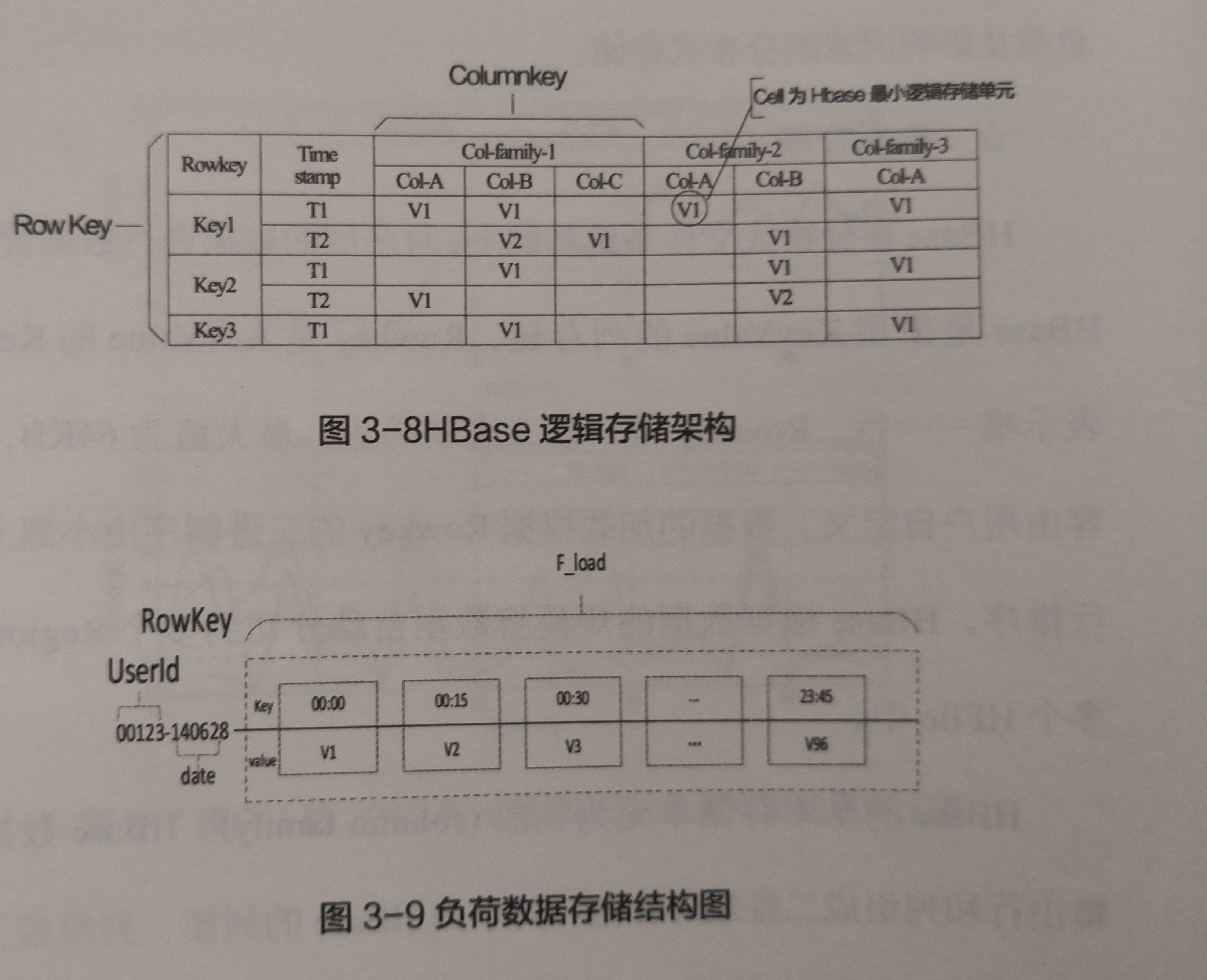
图3-8HBase逻辑存储架构
图3-9负荷数据存储结构图
☆数据计算
MapReduce具有分布式计算框架,以及顶层的应用集成和相关的协调功能。对于大数据方案来说,该负荷预测方案具体的分布式实现是我们关注的重点。因此,这里主要介绍该大数据预测方案的MapReduce分布式实现思想。图3-10是MapReduce的逻辑图。
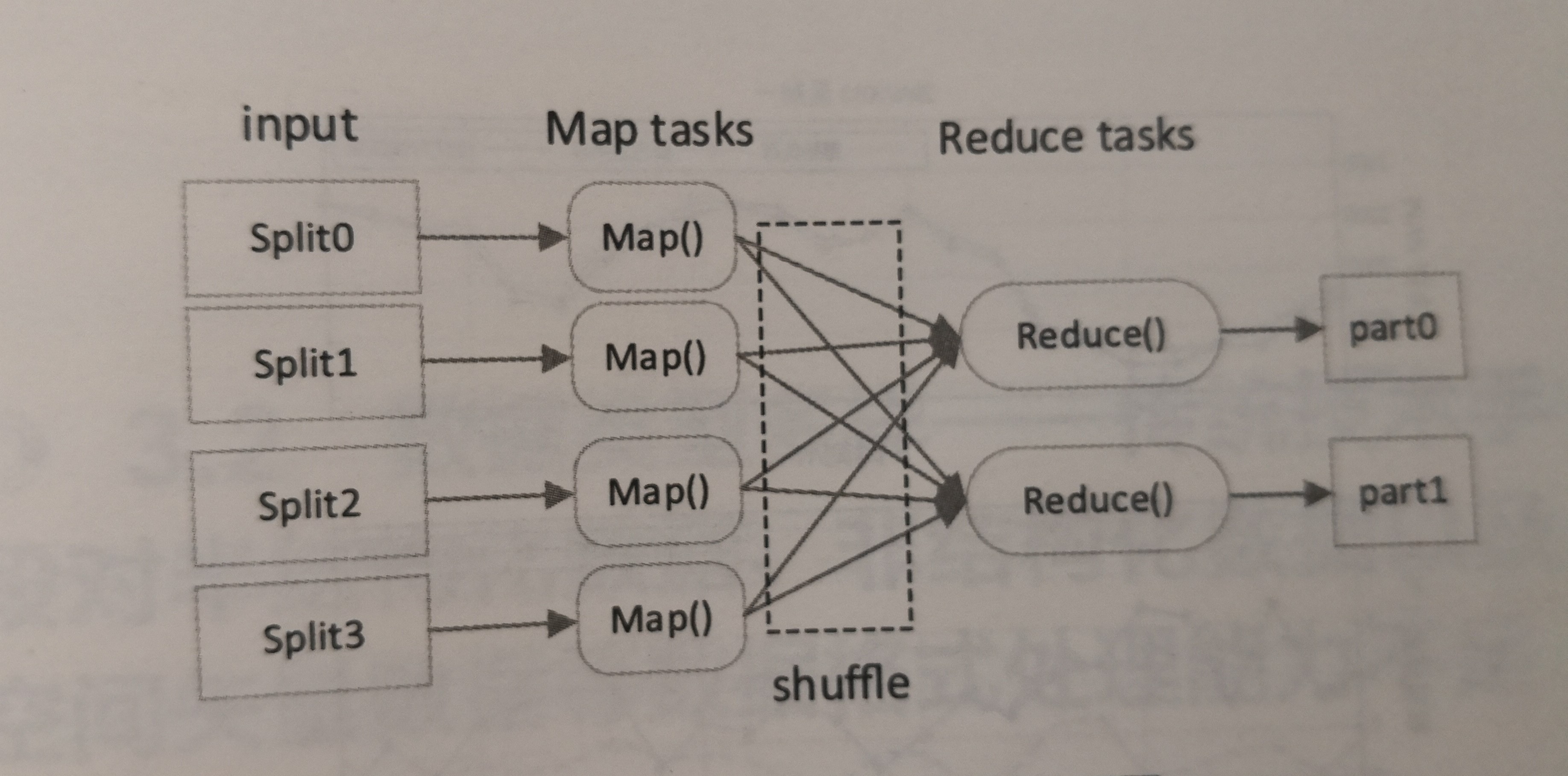
图3-10MapReduce逻辑处理图
其中,每一个Split代表的是一个数据段,读数据段为存储一个用户的全年历史负荷数据及相关因素数据;每一个MaP进程负责对每个用户进行步骤1~4的计算和分析;在Reduce环节,则完成对120万用户的数据整合,得出整个系统的总体负荷预测结果。
通过以上两部分的计算,得出的最终预测结果如图3-1所示

图3-11系统负荷预测结果
对上述120万个用户的负荷预测结果进行累加,即可得到最终的系统负荷,结果如图3-11所示。传统方法的最大相对误差为3.36%,最小相对误差为0,51%,平均相对误差为1.68%;而采用大数据方案得到的预测结果为:最大相対误差为1.35%,最小相对误差为O.O7%,平均相对現差为1.68%。因此,可以得出本方案取得了较传统方案好的预测结果。
书名:电力大数据:能源互联网时代的电力企业转型与价值创造
ISBN:978-7-111-51693-4
作者:赖征田
出版日期:2016-01
出版社:机械工业出版社