在发展历程上,大数据与云计算很类似,开始都搞不清是什么概念,但有很多人在说,难免南辕北辙。一个非常有趣现象:会有很多人说大数据不是什么,但很少有人说是什么。但这都不妨碍大数据成为产业发展趋势。
当务之急是不纠缠于概念,直接关注有哪些应用可以落地,可以采用哪些大数据技术。
技术三分天下
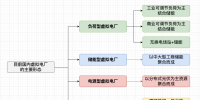
传统数据处理技术以数据库技术为主,主要应用在联机事物处理(OLTP)的应用场合,后来的数据仓库、数据集市都是数据库技术的发展和延伸。数据库技术已经有30年的历史,可以将其概括为一句话“一种架构支持所有应用”。数据库技术以结构化数据为主,而结构化数据也是价值密度最高的数据。而半结构化数据、非结构化数据价值密度相对比较低,如果采用传统数据库技术处理这些数据,会被认为得不偿失。
大数据时代,以Hadoop为代表的NoSQL技术,以列式数据处理为代表的MPP NewSQL技术应运而生,为半结构化数据、非结构化数据提供了技术支撑基础,以互联网企业为代表,创造了各种新的商业模式,也开启了大数据应用的时代。
在大数据时代,对于分析类应用的需求不断增加,特别对于传统行业/企业,大数据分析需求首先包括结构化数据,这已经分析了30多年,如今结构化数据分析需要与各种半结构化数据、非结构化数据分析相结合,用全数据的视野,指导行业/企业的业务应用和实践。这就导致一种架构难以完全满足大数据的需求,“多种架构支持多类应用”就成为了大数据处理应用的基本思路,出现了OldSQL、NewSQL和NoSQL三分天下的市场格局。
传统OldSQL数据库以Oracle、IBM DB2、Sybase等为主,NewSQL以EMC Greenplum、HP Vertica、SAPSybaseIQ、Teradata、IBM Netezza、微软PDW以及南大通用的Gbase 8a 为主;而NoSQL包括Cassandra、Mon goDB、CouchDB、Redis、Riak和Hbase等,丰富的产品技术为用户提供了丰富的选择。
混搭不可避免
大数据应用采用多种架构支撑不可避免。据中国移动业务支撑系统部高级工程师何鸿凌介绍,中国移动就采用了MPP和Hadoop混搭架构,配合原有数据仓系统,开展大数据的应用。其中,传统DW(数据仓库)做高价值数据,也就是结构化数据的加工,MPP做长期结构化数据的存储和自助分析,Hadoop用于非结构化数据处理、挖掘和历史存储。
何鸿凌表示,MPP是将传统分布式数据库的理论运行在X86上的实践,用列存、内存和副本等进行了优化。MPP基本可以替代传统DW,但在大数据时代,还是有挑战。那就是由于它精确地进行数据分布的原因,可扩展性和高可用比较难以达到。按照CAP理论,一种系统不可能什么都追求。因此国内较大的MPP集群也就几十个节点,国际上可以看到100~200节点的集群。根据中国移动数据处理得需求,起码也需要300~400个节点。
“大数据主要是要应用,而现在很多的应用都不是由IT开发的,是自助的,这就需要MPP中要提供沙盒,让业务部门或第三方能自助地分析和开发。我们当然不希望每个沙盒都是物理的MPP集群,这样不仅安装维护复杂,而且会造成数据重复。所以我们希望的是让MPP的能力像云计算那样对外提供按需服务,实现虚拟化。”他说。
谈到Hadoop,中国移动认为Hbase和HDFS很好,但Map/Reduce使用起来需要一些技术能力,Hadoop 2.0中Map/Reduce已经不再是唯一的执行框架,而缩减为Yarn框架下的一个应用了。对于Hadooperyan,其优势在于数据处理的成本,较之数据仓库内廉价很多,但在效率上还有差距,这是其数据分布策略所造成所的,这也是为什么中国移动还要选择MPP进行混搭因。
Hadoop技术难点主要是在Map/Reduce、各个作业之间都需要落地到HDFS上,这个效率会很差,而且没有全局优化。Spark解决了这些问题,包括用内存缓存、流水线和全局优化,因此中国移动用Spark作为处理引擎。据了解,中国移动准备将长期数据放到Hadoop上做自助查询,既能缩小MPP的规模,也能降低成本,当然这样的查询效率就不如在MPP上了。
大数据应用落地情况
混搭也好,多种模式也好,运用这些框架和技术手段的大数据应用,究竟会对现有模式产生哪些影响呢?大数据应用又是怎么样落地接地气的呢?也许中国移动的大数据应用实践会给我们一些启示。
总结来看,中国移动大数据应用有三个方面:一是让中国移动现有商业模式更加有竞争力;二是发掘新的商业模式,让别的行