▲吴甘沙
我做了4-5年的移动架构和Java虚拟机,4-5年的众核架构和并行编程系统,最近4-5年在追时髦,先是搞物联网,最近几年一直在做大数据。我们大数据的研究轨迹如下图所示:前面2-3年主要是关注数据和机器的关系,水平扩展、容错、一致性、软硬件协同设计,还有就是厘清各种计算模式,从批处理(MapReduce)到流处理、Big SQL/ad hoc query、图计算和机器学习。事实上我的团队只是英特尔大数据研发力量的一部分,上海的团队是英特尔Hadoop发行版的主力军,因为英特尔成了Cloudera的最大股东,自己不做发行版了,但是平台优化、开源支持和垂直领域的解决方案仍然是英特尔大数据研发的重心。
2013年开始看数据与人的关系,对于数据科学家怎么做好分布式机器学习、特征工程与非监督学习,对于领域专家来说怎么做好交互式分析工具,对于终端用户怎么做好交互式可视化工具。英特尔研究院在美国CMU支持的科研中心做了GraphLab、Stale Synchronous Parallelism,在MIT的科研中心做了交互式可视化(真正做这个工作的教授在UW)和SciDB上的大数据分析,我们中国周边主要做了Spark SQL和MLlib(机器学习库)。现在也有涉及深度学习算法和基础设施。
2014年开始看数据和数据的关系。

▲
为什么要琢磨数据和数据的关系呢?我们原来的工作重心是开源,后来发现开源只是开放式创新的一个部分,做大数据的开放式创新还要做数据的开放,大数据基础设施的开放,以及价值提取能力的开放。
这是一张非常有意思的图,黄色部分是化石级的、还没有联网、或者没有数字化的数据,而绝大多数的数据是在这么一个海里面。只有海平面的这些数据(有的把它称为Surface Web),才是真正大家能访问到的数据,爬虫能爬到、搜索引擎能检索的数据,而绝大多数的数据是在暗黑之海里面(相应地叫做Dark Web,据说占数据总量的85%以上),在一些孤岛里面,在一些企业、政府里面躺在地板上睡大觉。

▲
数据之于数据社会,就如同水之于城市或者血液之于身体。城市因为河流而诞生,也受其滋养,血液一旦流动停滞了,身体就有危险。所以,对于号称数据化生存的社会来说,我们一定要让数据流动起来,不然这个社会将会失去很多功能。
所以,我们希望数据能够像“金风玉露一相逢,便产生化学作用”。马化腾先生提出了一个internet+,internet可以帮助各行各业,我们也杜撰了一个大数据X,大数据乘以各行各业。如下图所示,乘法效应之外,数据有个非常奇妙的效应叫做外部效应(externality),比如这个数据对我没用但对TA很有用,所谓我之毒药彼之蜜糖。张家的数据和赵家的数据各自都没啥活性,一碰到一起就发生化学作用。
在这张胶片上列出了一些数据跨行业融合的案例。比如说:
金融数据跟电商数据碰撞在一起,就产生了像小微贷款那样的互联网金融;
电信数据跟政府数据碰在一起,可以产生人口统计学方面的价值,帮助城市规划人们居住、工作、娱乐的场所;
金融数据跟医学数据碰在一起,麦肯锡列举了很多应用,比如说可以发现骗保;
物流数据和电商数据凑一块,可以了解各个经济子领域的运行情况;
物流数据跟金融数据放在一起,就产生了供应链金融;
金融数据跟农业数据也能够发生一些化学作用,Google analytics出来的几个人,利用美国开放气象数据,能够在每一块农田上面建立微气象模型,预测灾害,帮助农民保险和理赔。

▲
所以,要走数据开放之路,让不同领域的数据真正流动起来、融合起来,才能释放大数据的价值。
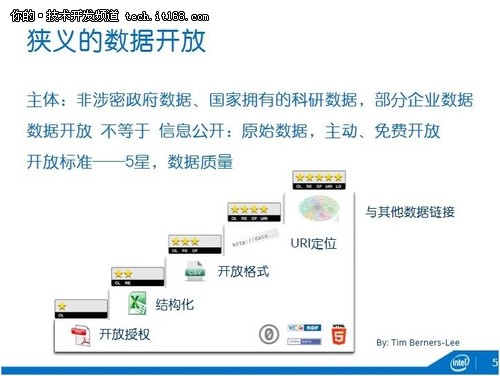
先来看狭义的数据开放(下一张slide)。数据开放的主体首先是政府和科研机构,把非涉密的政府数据,以及国家拿纳税人的钱做的一些科研数据开放出来。现在也有一些企业愿意开放数据,像Netflix、一些电信运营商,来帮助他们的数据价值化,建构生态系统。
数据开放不等于信息公开。首先,数据不等于信息,信息是从数据里面提炼出来的东西。我们希望,首先要开放原始的数据(raw data)。其次,它是一种主动和免费的开放,我们现在经常听说要申请信息公开,那是被动的开放。
Tim Berners Lee提出了数据开放的五星标准,以保证数据质量:一星是开放授权的格式,比如说PDF;其次是结构化,把数据从文件变成了像excel这样的表;三星是开放格式,如CSV;四星是能够通过URI找到每一个数据项;五星,能够跟其它数据链接,形成一个开放的数据图谱。
▲
下面这张slide讲数据开放的形态。现在主流的数据开放门户,像data.dov或data.gov.uk,都基于开源软件。Data.gov用WordPress做数据内容呈现,用CKAN做数据目录,甚至data.gov自身也在github开源了。
英特尔在MIT的大数据科研中心也做了一种形态,叫Datahub,你看它的吉祥物很有趣,一半是大象,代表数据库技术,一般是章鱼,取自github的吉祥物章鱼猫。它提供更多的功能,如:
-
易管理性,可以容易地检索、合并和清洗数据;
-
像数据库那样的结构化数据服务;
-
安全方面,提供访问控制,对数据共享进行管理;
-
最后,它可以在原地(in-situ)做可视化和分析,现在一般要把数据从开放门户下载下来,然后在另外一个系统里做可视化和分析,这个能在原地做。
-

▲
数据开放当中会碰到很多问题(下图),首先是数据权属的问题,这个数据属于谁?属于采集人,还是属于生产人,还是属于被观察的客体?如果发生一些特别情况的话,它的拥有权是不是会出现一些分割或者转移?比如说离婚了,比如说人死了,这样数据资产怎么转移?
另外就是敏感数据的界定,数据里面有很多敏感的部分,比如说欧洲GPS位置信息的数据是属于敏感数据,在日本又不属于敏感数据。所以,这需要一个法律的界定。
针对这些敏感数据要做数据的脱敏,脱敏最初级的一种做法就是去标识化,但是去标识化一定要去的彻底。美国做过一个研究,如果把名字、地址什么都拿掉,但你只要剩下三个信息:邮政编码、性别、生日,只要根据这三个信息,你还是有60-90%的可能性,把人还原出来。
当然,你即使是去标识去的很彻底,你还是要防止重新标识化(re-identification),比如你可以通过多数据源来重新进行标识。美国在线曾经开放了匿名的搜索信息,但是有人把这个信息跟美国的选举人登记信息一匹配,就把人找出来了。Netflix也是一样,他开放了匿名的评论以及打分的信息,但是有人把它跟国际电影数据库IMDB匹配,结果把一个有同性恋倾向的人识别了出来,被告了。另外一种重新标识的可能性是基于统计,比如根据两个打分再加上一定的时间范围,还是有接近70%的可能性能够把这个人找出来。
防止隐私攻击的匿名化技术,比较典型的如k-anonymity和L-diversity等等,但还是有隐私攻击的可能,特别在敏感属性不够多样化,或攻击者具有背景知识时。最好的一种技术叫差分隐私(differential privacy),把噪声加入到数据集中、但仍保持它的一些统计属性,英特尔支持普林斯顿大学做了这样的研究,现在试图在运营商开放数据中应用。

▲
以上是狭义的数据开放,广义的数据开放还有数据的共享及交易(下图),比如点对点进行数据共享或在多边平台上做数据交易。
马克思说生产资料所有制是经济的基础,但是现在大家可以发现,生产资料的租赁制变成了一种主流(参考《Lean Startup》),在数据的场景下,我不一定拥有数据,甚至不用整个数据集,但可以租赁。租赁的过程中要保证数据的权利。
首先,我可以做到数据给你用,但不可以给你看见。姚期智老先生82年提了个“millionaires’ dilemma”问题,两个百万富翁比富,但谁都不愿意说出自己有多少钱。这就是典型的“可用但不可见”场景。在实际生活中的例子很多,我一直用的一个例子是:美国国土安全部有恐怖分子名单(数据1),航空公司有乘客飞行记录(数据2),国土安全部去问航空公司要乘客飞行记录,航空公司不给,因为隐私,他反过来问国土安全部要恐怖分子名单,也不行,因为是国家机密。双方都有发现恐怖分子的意愿,但都不一样给出数据,有没有办法让数据1和数据2放一起扫一下,但又保障数据安全呢?
其次,在数据使用过程中要有审计。万一那个扫描程序偷偷把数据藏起来送回去怎么办?
再者,需要数据定价机制,双方数据的价值一定不对等,产生的洞察对各方的用途也不一样,因此要有个定价机制,比大锅饭式的数据共享更有激励性。
从点对点的共享,最后要走到多边的数据交易,从一对多的数据服务到多对多的数据市场,再到数据交易所,如果说现在的数据市场更多是对数据集进行买卖的话,而这个数据交易所是一个基于市场进行价值发现和定价的,像股票交易所那样的、小批量、高频率的数据交易。

▲
我们支持了不少研究来实现刚才说的这些功能,比如说可用而不可见。案例一是通过加密数据库CryptDB/Monomi(下图),这也是我们支持麻省理工学院做的一个技术。在数据拥有方甲方这边的数据库是完全加密的,这事实上也防止了现在出现的很多数据泄露问题,大家已经听到,比如说某互联网服务提供商的员工偷偷把数据拿出来卖,你的数据一旦加密了他拿出来也没用。其次,这个加密数据库可以运行乙方的普通SQL程序。因为它采用了同态加密技术和洋葱加密法,SQL的一些语义在密文上也可以执行。

▲
针对类似百万富翁窘境,我们针对此做了另一种可用但不可见的技术,叫做数据咖啡馆(下图)。大家知道咖啡馆是让人和人进行思想碰撞的地方(顺便推荐Steven Johnson的TED演讲, where good ideas come from),我们这个数据咖啡馆就是让数据和数据能够碰撞,产生新的价值。
比如两个电商一个是卖衣服的一个是卖化妆品的,他们对于客户的洞察都是相对有限的,如果说两边的数据放在一起做一次分析,那么就能够获得全面的用户画像。再如,癌症研究,癌症是一类长尾病症,有太多的基因突变,每一个研究机构的基因组样本都相对有限,这在某种程度上解释了为什么过去50年癌症的治愈率仅仅提升了8%。那么,多个研究机构的数据在咖啡馆碰一碰,也能够加速癌症的研究。
在咖啡馆的底层是一个多方安全计算的技术,基于英特尔跟伯克利的一个联合研究。在上面是安全、可信的Spark,基于“data lineage”的使用审计,还有就是根据各方数据对结果的贡献进行定价。有可能一家电商是新的,他还没有太多的数据,这就碰到一个机器学习冷启动的问题,那么我可以运用另外一家电商数据,做所谓的transfer learning,帮助他解决这个冷启动的问题。很显然,另外那家电商的数据价值就应该更高。

▲
把数据定价拔高一点。我们数据社会的经济基础是什么?一定要有一些基本规律。大家知道,互联网经济有个基本规律叫Metcalf定律,应该是Gilder提出的,为致敬以太网发明人Metcalf而命名。它是说一个网络的价值是跟你的节点数平方成正比。它的另一种表述是网络效应或网络外部性:随着网络使用者的不断增多,每一个使用者从中获得的价值不断增加,但使用费用则不断下降。这奠定了互联网的需求方规模经济的商业模式,后面的所谓“边际成本趋向于零”、“边际效益递增”、“正向反馈”、“马太效应”和“赢家通吃”等皆由此衍生而出。而如今互联网公司的通用估值方法,股票价值折现分析法或DEVA估值法,也是90年代一些分析师基于此提出的:一个网络公司的价值是跟他的用户数平方成正比的。这种巴菲特不能理解、但又符合规律的估值方法帮助年年亏损的互联网公司融到了大笔资金,也解释了Facebook上市前能够估值千亿美元,不是因为它的营业额(40多亿)或利润(不到10亿),而是因为它的8亿用户量。Google有个首席经济学家Hal Varian,这哥们在90年代末写了一本书,名字大致是信息时代的规则,当时卖得比KK的《新经济、新规则》好很多(现在KK的这本书卖得很好了,不同时代的口味是不一样)。Varian的团队专门研究互联网和经济的交叉学科。
那么,大数据时代的Metcalf定律是什么呢?
我们也不知道,一来从实践中摸索,二来有意识地跟经济界做思想碰撞。

▲
比如(下图),数据在公开市场交易的时候,该怎么定价?是根据市场价值发现机制来定价?还是根据数据的种类来定价?还是根据数据访问API的调用次数来定价?
在点对点的时候,各方的数据对于智慧产生的贡献不一样,也需要定价。
现在企业的资产中有一部分无形资产是数据资产。那么,这怎么来提升我们企业的估值?这部分数据资产价值几何?现在也有一些很好的研究,比如consumption based model。
个人数据也需要定价,大家知道现在个人数据几乎是免费的,我们为了获得互联网服务提供商的免费服务,把数据免费给了服务提供商。但是,现在国外对于小数据、对于个人数据有价,已经开始觉醒了。有一个初创公司愿意给消费者一部分钱,你把你的Facebook数据、推特数据、银行交易数据给这家公司,他来价值化(比如找广告商)。现在的定价很简单,女性一个月14美金(女性的消费能力强啊),男性一个月8美金,未来该怎么定价也是个很有意思的话题。
在共享交易当中也注意伪造的数据或劣质的数据,有人在共享的时候把一些假的数据、杂质数据放进去怎么办?这也是很有意思的问题,而且很现实。Snowdon的文件解释英国情报机构GCHQ就很善于在网络数据中掺假,改变网络民意或热点,创造虚假流量。

▲
前面说的是数据的开放,下面很快说一下另外两种开放。
一是大数据基础设施的开放(下图),现在有的是有大数据思维的人,但他们很捉急,玩不起、玩不会大数据,他不懂怎么去存储、怎么处理这些大数据,这就需要云计算。如果说数据开放是Data as a Service,基础设施的开放还是传统的Platform as a Service,比如Amazon AWS里有MapReduce,Google有Big Query。这些大数据的基础处理和分析平台可以来降低数据思维者的门槛,来释放他们的创造力。
比如decide.com,每天爬几十万的数据,对价格信息(结构化的和非结构化的)进行分析,然后告诉你买什么牌子、什么时候买最好。只有四个PhD搞算法,其他的靠AWS。
另一家公司Prismatic,也利用了AWS,这是一家做个性化阅读推荐的,我专门研究过它的计算图、存储和高性能库,用LISP的一个变种Clojure写的,非常漂亮,真正做技术的只有三个学生。
所以当这些基础设施社会化以后,大数据思维者的春天很快就要到来。

▲
最后一种开放是价值提取能力的开放(下图)。现在的模式一般是一大一小或一对多。比如Tesco和Dunnhumby,后者刚开始是很小的公司,傍上了Tesco,给它做客户忠诚度计划,一做就做了几十年,这样的长期的战略合作优于短期的数据分析服务,决策更注重长期性。当然,Dunnhumby现在已经不是小公司了,Tesco控股,也为其他大公司提供数据分析服务。沃尔玛跟另外一家小公司合作做数据分析,最后他把这家小公司买下来了,成了它的Walmart Labs。
一对多的模式,典型的是Palantir,Peter Thiel和斯坦福的几个教授搞的公司,目前还是私有的,但估值近百亿了,它很擅长给各类政府和金融机构提供数据价值提取服务。
真正把这种能力开放的是Kaggle,它的双边,一边是10万多的分析师,另一边是需求方企业,企业在Kaggle上发标,分析师竞标,获得业务。这可能是真正解决长尾公司价值提取能力的办法。这个如果跟我们的数据咖啡馆结合,那就更好了。

▲
好,今天就讲到这,谢谢大家!