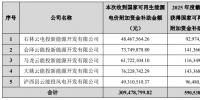
德国斯图加特大学的科研人员利用超级计算机和机器学习开发出一套工具,可帮助火电厂、核电厂、地热电厂等改善运营效率。
高性能计算资源和数据驱动的机器学习帮助德国斯图加特大学(University of Stuttgart)的科研人员建模,指导火电厂、核电厂、地热电厂运营升级,变得更清洁、安全、高效。
传统火力发电厂的残余水必须与发电产生的蒸汽分开。这一流程限制了效率,而且在早几代发电厂中,它还不稳定,可能导致爆炸。上世纪二十年代,英国人马克·本森(Mark Benson)意识到,如果水和蒸汽可以共存,就能降低这种风险,提高发电厂效率。让水处于超临界状态,即,水的液态和气态同时存在,成为一种新的液体,这时就能实现水和蒸汽的共存。要实现这种超临界状态所需的温度和压力条件的成本很高,使得本森的专利产品“本森锅炉”没有在发电厂中广泛应用,但他的理论让世界首次认识了超临界发电技术。
大约过了一个世纪,德国斯图加特大学的核技术与能源系统研究所(Institute of Nuclear Technology and Energy Systems, IKE)及航天热力学研究所(Institute of Aerospace Thermodynamics, ITLR)重新研究本森的理论,探索其如何提高现代发电厂的安全性和效率。科研人员利用高性能计算技术(HPC)开发工具,让超临界热传递更可行。研究人员指出,“与亚临界发电厂相比,超临界发电厂的热效率更高,不用配备多种类型设备,例如各类蒸汽干燥器,布局更紧凑。”
航天热力学研究所的研究人员牵头该研究的计算部分,他们与新加坡理工大学(Singapore Institute of Technology, SIT)的计算机科学研究人员合作,在超级计算机上开发基于高保真仿真的机器学习技术,同时也开发商业电脑能轻松应用的工具。
为了构建出可商业应用的准确工具,研究团队需要运行计算密集型直接数值模拟(direct numerical simulation, DNS),这只能利用高性能计算资源才能实现。斯图加特高性能计算中心(High-Performance Computing Center Stuttgart’s, HLRS’s)的Hazel Hen超级计算机完成了研究团队所需的高分辨率流体力学模拟。
发电机及其他工业流程通过多种材料来产生蒸汽或者进行热传递,但利用水是一种行之有效的方法——水可轻易获得,其化学性质已充分掌握,可预测其在各种温度及压力条件下的表现。具体而言,水预计在374摄氏度达到临界点,这一性质让超临界状态蒸汽的产生可顺利进行。水也需要处于高压状态——22.4兆帕斯卡,实际上超过了厨房水槽处压力的200倍。而且,当材料进入超临界状态时,它会表现出独特的性质,温度或压力的微小改变都会带来极大的影响。例如,超临界状态的水不如纯液态水传热那么有效,达到超临界状态所需的极大热量可能导致管道破坏,从而造成灾难性事故。
考虑到利用水的种种困难,研究人员正在研究使用二氧化碳。这种常见分子具有多种优势,主要特点是在31摄氏度即达到超临界状态,比水要高效得多。利用二氧化碳来让发电厂变得更清洁,听上去可能显得自相矛盾,但研究人员解释说超临界状态的二氧化碳是一种更清洁的选择。
“与含氯氟烃的制冷剂、氨等其他常见的可用流体相比,超临界状态的二氧化碳绝不会破坏臭氧,对全球变暖几乎没有影响。”此外,这种状态的二氧化碳所需空间要小得多,压缩所需的工作也比超临界状态的水要少得多。这就意味着,使用二氧化碳所需的发电厂规模更小——超临界状态二氧化碳发电厂的发电循环硬件规模比传统的超临界状态发电循环系统要小十倍。但要用二氧化碳替代水,工程师还需要充分理解其根本性质,包括流体的湍流(即不均匀非稳定流动)如何传递热量、与机器相互作用。
在进行湍流相关的计算流体力学模拟时,计算科学家大部分采用这三种方法:雷诺平均(Reynolds-Averaged Navier-Stokes, RANS)模拟、大涡模拟(large eddy simulations, LES)、直接数值模拟。雷诺平均和大涡模拟都需要研究人员纳入来自实验或者其他模拟的一些假设,直接数值模拟无需预想概念或输入数据,使得这种方法更准确,但需要更多的计算资源。“雷诺平均和大涡模拟模型常用于更简单的流体。”研究人员说,“复杂流体需要高保真的方法,所以我们决定使用直接数值模拟,这让我们需要高性能计算资源。”
研究团队与新加坡理工大学的科研人员合作,利用从高保真直接数值模拟得到压力和热传递数据来训练深度神经网络(DNN)。这种机器学习算法仿生物学神经网络建模,即模仿识别和响应外部刺激的神经元网络。
传统上,研究人员利用实验数据来训练机器学习算法,以便其预测不同条件下流体和管道之间的热传递。但是,如果采用这种方法,研究人员必须小心翼翼,不“过度拟合”模型;换言之,不让算法对特定数据集过于准确,而不能为其他数据集提供准确结果。
利用Hazel Hen超级计算机,该研究团队运行了35个直接数值模拟,每一种聚焦于一种具体的运行条件,然后利用得到的数据集来训练深度神经网络。该研究团队输入了进气温度和压力、热流、管径和流体的热能,输出管壁温度和剪切应力。直接数值模拟产生的数据中,随机选择80%来训练深度神经网络,同时研究人员利用剩下的20%来单独验证。
这种“原位”验证很重要,避免过度拟合算法,因为如果算法一开始表现出训练与数据集的差异,就会重启模拟。研究人员表示,“我们的盲法测试结果显示,直接数值模拟成功避免了过度拟合,在数据库中覆盖的各种运行条件下都实现了普遍的接受性。”
研究团队对结果有信心之后,他们利用数据开始构建更商业化用途的工具。利用近期工作的输出作为指导,该团队可用直接数值模拟在标准笔记本电脑上对新数据模拟运行条件的热能,耗时仅5.4毫秒。
到目前为止,研究团队都使用社区代码OpenFOAM进行直接数值模拟。对多种流体力学模拟而言,OpenFOAM都是公认的代码,但是研究人员表示,希望利用高保真代码进行模拟。研究人员正与德国斯图加特大学空气力学与气体力学研究所(Institute of Aerodynamics and Gas Dynamics, IAG)合作,使用后者的FLEX代码。这种代码的准确性更高,适用的条件范围更广。
研究人员还提到,除了直接数值模拟之外,他们还使用了名为隐式大涡模拟的方法。虽然隐式大涡模拟不如该研究团队直接数值模拟得到高分辨率,但这种方法让研究人员以更高的雷诺数值进行模拟,这意味着它能适用的湍流条件更广。
研究团队希望继续增强它的数据库,以便进一步提升深度神经网络工具。而且,研究团队还与该大学的核技术与能源系统研究所实验家合作,进行初步实验,建立模型超临界发电厂,以便测试实验与理论的一致性。如果研究团队能提供准确、易用且计算高效的工具,帮助工程师和发电厂管理者更安全、更高效地发电,这就是最终胜利。
“核技术与能源系统研究所的研究人员既进行实验也进行数值模拟。”研究人员表示,“作为数值团队,我们希望找到热传递不高的原因。我们研究了流体流动和湍流相关的物理学,但是我们的最终目标是构建出更简单的模型。传统发电厂通过抵消间歇式发电,促进可再生能源的使用,但是目前这些发电厂的设计都不如可再生能源发电厂那样灵活。如果我们可以利用超临界状态二氧化碳为基础的工作流体,我们就能通过更紧凑的设计、更快的开机和停机次数来提高发电厂的灵活性。”以超临界状态二氧化碳为基础的技术有可能提供灵活的运行,这是可再生能源中翘首以盼的。但是,水暖水力模型和热传递知识有限,本研究将缩小这一技术差距,帮助工程师构建发电循环回路。
该大学核技术与能源系统研究所和航天热力学研究所的科研人员正在研究超临界状态二氧化碳取代超临界状态水作为发电厂的工作流体。这一模拟显示了冷却过程中流体的高速(红)和低速(蓝)条带及结构。研究人员观察到了超临界状态二氧化碳下行流(左)和上行流(右)湍流之间的重要区别。